建立機器學習開發環境
本文介紹在本地機器上學習機器學習的第一步:建立開發環境。所有內容都是基於Ubuntu 20.04 LTS和NVIDIA Geforce RTX 3070顯卡撰寫的。
概述
本文介紹在本地機器上學習機器學習的第一步:建立開發環境。所有內容都是基於Ubuntu 20.04 LTS和NVIDIA Geforce RTX 3070顯卡撰寫的。
- 要建立的技術堆疊
- Ubuntu 20.04 LTS
- Python 3.8
- pip 21.0.1
- jupyter
- matplotlib
- numpy
- pandas
- scipy
- scikit-learn
- CUDA 11.0.3
- cuDNN 8.0.5
- 深度學習框架(建議每個環境只選擇安裝一個)
- PyTorch 1.7.1
- TensorFlow 2.4.0
與新撰寫的機器學習開發環境建立指南的比較表
雖然這篇文章發布已經過了約3年半,但除了套件版本和NVIDIA開源驅動發布等一些細節外,整體內容仍然有效。然而,在人類紀元 12024年夏天購買新電腦並建立開發環境時,有一些變更,因此我撰寫了新的開發環境建立指南。差異如下表所示:
| 差異點 | 本文 (12021版本) | 新文章 (12024版本) |
|---|---|---|
| Linux發行版 | 以Ubuntu為基準 | 除了Ubuntu外,也適用於Fedora/RHEL/Centos, Debian, openSUSE/SLES等 |
| 開發環境建立方式 | 使用venv的Python虛擬環境 | 使用NVIDIA Container Toolkit的 Docker容器環境 |
| 安裝NVIDIA顯卡驅動 | O | O |
| 在主機系統上 直接安裝CUDA和cuDNN | O (使用Apt套件管理器) | X (使用Docker Hub上NVIDIA提供的預安裝映像, 因此不需要直接操作) |
| 可移植性 | 每次轉移到其他系統時 都需要重新建立開發環境 | 基於Docker,可以使用已製作的Dockerfile 隨時建立新映像,或輕鬆移植現有映像 (不包括額外的卷或網絡設定) |
| 使用cuDNN外的 其他GPU加速庫 | X | 引入CuPy, cuDF, cuML, DALI |
| Jupyter Notebook介面 | Jupyter Notebook (classic) | JupyterLab (Next-Generation) |
| SSH伺服器設定 | 未涵蓋 | 第3部分包含基本SSH伺服器設定 |
如果你想使用venv等Python虛擬環境而非Docker,這篇文章仍然有效,可以繼續閱讀。如果你想享受Docker容器的高可移植性等優點,或計劃使用Ubuntu以外的Linux發行版如Fedora,或使用NVIDIA顯卡並想利用CuPy、cuDF、cuML、DALI等額外的GPU加速庫,或想通過SSH和JupyterLab設定進行遠程訪問,建議也參考新指南。
0. 前置檢查事項
- 學習機器學習建議使用Linux。雖然Windows上也可以,但在許多細節上可能會浪費時間。使用Ubuntu最新LTS版本是最穩妥的選擇。它會自動安裝非開源的專有驅動程式,而且由於用戶眾多,大多數技術文檔都是以Ubuntu為基準撰寫的。
- 一般來說,Ubuntu和大多數Linux發行版都預裝了Python。但如果沒有安裝Python,在按照本文操作前,需要先安裝Python。
- 可以用以下命令檢查當前安裝的Python版本:
1
$ python3 --version
- 如果要使用TensorFlow 2或PyTorch,需要檢查兼容的Python版本。在撰寫本文時,PyTorch最新版支持的Python版本是3.6-3.8,TensorFlow 2最新版支持的Python版本是3.5-3.8。
本文使用Python 3.8版本。
- 可以用以下命令檢查當前安裝的Python版本:
- 如果計劃在本地機器上學習機器學習,建議準備至少一個GPU。雖然數據預處理可以用CPU完成,但在模型訓練階段,隨著模型規模增大,CPU和GPU的學習速度差異會非常顯著(尤其是深度學習)。
- 對於機器學習,GPU製造商的選擇實際上只有一個:NVIDIA。NVIDIA在機器學習領域投入了大量資源,幾乎所有機器學習框架都使用NVIDIA的CUDA庫。
- 如果計劃將GPU用於機器學習,首先要確認你的顯卡是否支持CUDA。可以在終端中使用
uname -m && cat /etc/*release命令檢查當前電腦的GPU型號。在此連結的GPU列表中找到相應型號,檢查其Compute Capability值。這個值至少要達到3.5才能使用CUDA。 - GPU選擇標準在以下文章中有很好的整理,作者持續更新這篇文章:
Which GPU(s) to Get for Deep Learning
同一作者的A Full Hardware Guide to Deep Learning也非常有用。該文的結論如下:RTX 3070和RTX 3080是強大的顯卡,但記憶體略顯不足。然而,對於許多任務,你並不需要那麼多記憶體。
RTX 3070對於學習深度學習來說是完美的。這是因為大多數架構的基本訓練技能可以通過稍微縮小規模或使用稍小的輸入圖像來學習。如果我要重新學習深度學習,我可能會選擇一張RTX 3070,如果有多餘的錢,甚至會選擇多張。 RTX 3080目前是最具成本效益的顯卡,因此非常適合原型設計。對於原型設計,你需要最大的記憶體,同時又要價格便宜。這裡的原型設計指的是任何領域的原型設計:研究、Kaggle競賽、為創業公司開發想法/模型、實驗研究代碼。對於所有這些應用,RTX 3080是最佳GPU。
如果滿足上述所有條件,就可以開始建立工作環境了。
1. 創建工作目錄
打開終端,修改.bashrc文件以註冊環境變數($提示符後面是命令)。
首先使用以下命令打開nano編輯器(也可以使用vim或其他編輯器):
1
$ nano ~/.bashrc
在最後一行添加以下內容。雙引號內的內容可以根據需要更改為其他路徑:
export ML_PATH="$HOME/ml"
按Ctrl+O保存,然後按Ctrl+X退出。
現在執行以下命令應用環境變數:
1
$ source ~/.bashrc
創建目錄:
1
$ mkdir -p $ML_PATH
2. 安裝pip套件管理器
安裝機器學習所需的Python套件有多種方法。可以使用Anaconda等科學Python發行版(Windows操作系統推薦的方法),也可以使用Python自己的打包工具pip。這裡我們將在Linux或macOS的bash shell中使用pip命令。
使用以下命令檢查系統是否已安裝pip:
1
2
3
4
5
6
$ pip3 --version
找不到命令'pip3'。但可以通過以下方式安裝:
sudo apt install python3-pip
如果出現上述訊息,表示系統未安裝pip。使用系統的套件管理器(這裡是apt)安裝(如果顯示版本號,則表示已安裝,可以跳過此命令):
1
$ sudo apt install python3-pip
現在系統已安裝pip。
3. 創建獨立的虛擬環境(推薦)
要創建虛擬環境(避免與其他項目的庫版本衝突),需要安裝venv:
1
$ sudo apt install python3-venv
然後創建獨立的Python環境。這樣做是為了防止不同項目所需的庫版本衝突,因此每次開始新項目時,都應創建新的虛擬環境以建立獨立環境:
1
2
$ cd $ML_PATH
$ python3 -m venv --system-site-packages ./(環境名稱)
要激活此虛擬環境,打開終端並輸入以下命令:
1
2
$ cd $ML_PATH
$ source ./(環境名稱)/bin/activate
激活虛擬環境後,升級虛擬環境中的pip:
1
(env) $ pip install -U pip
之後要停用虛擬環境,使用deactivate命令。在環境激活狀態下,使用pip命令安裝的任何套件都將安裝在這個獨立環境中,Python將使用這些套件。
3′. (不創建虛擬環境的情況)升級pip版本
在系統上安裝pip時,會從發行版(這裡是Ubuntu)的鏡像服務器下載二進制文件進行安裝,這些二進制文件通常更新較慢,可能不是最新版本(作者的情況是安裝了20.3.4版本)。要使用最新版本的pip,執行以下命令在用戶的主目錄中安裝(或升級)pip:
1
2
3
4
5
$ python3 -m pip install -U pip
Collecting pip
(省略)
Successfully installed pip-21.0.1
可以看到pip已安裝為撰寫本文時的最新版本21.0.1。此時,安裝在用戶主目錄中的pip系統無法自動識別,因此需要將其註冊為PATH環境變數,使系統能夠識別和使用它。
再次用編輯器打開.bashrc文件:
1
$ nano ~/.bashrc
這次尋找以export PATH=開頭的行。如果後面沒有路徑,就像第1步那樣添加內容。如果已有其他註冊路徑,使用冒號在後面添加內容:
export PATH="$HOME/.local/bin"
export PATH="(現有路徑):$HOME/.local/bin"
使用系統套件管理器以外的方法升級系統pip可能會因版本衝突而導致問題。這就是為什麼要在用戶主目錄中單獨安裝pip的原因。出於同樣的原因,在非虛擬環境中,建議使用python3 -m pip命令而非pip命令來使用pip。
4. 安裝機器學習套件(jupyter, matplotlib, numpy, pandas, scipy, scikit-learn)
使用以下pip命令安裝所需的套件及其依賴項:
作者使用venv,所以直接使用pip命令,但如果不使用venv,建議使用前面提到的python3 -m pip命令:
1
2
3
4
5
6
(env) $ pip install -U jupyter matplotlib numpy pandas scipy scikit-learn
Collecting jupyter
Downloading jupyter-1.0.0-py2.py3-none-any.whl (2.7 kB)
Collecting matplotlib
(後略)
如果使用了venv,為Jupyter註冊核心並命名:
1
(env) $ python3 -m ipykernel install --user --name=(核心名稱)
現在可以使用以下命令啟動Jupyter:
1
(env) $ jupyter notebook
5. 安裝CUDA & cuDNN
5-1. 確認所需的CUDA & cuDNN版本
在PyTorch官方文檔中確認支持的CUDA版本:

PyTorch 1.7.1版本支持的CUDA版本有9.2、10.1、10.2和11.0。NVIDIA 30系列GPU需要CUDA 11,所以我們需要11.0版本。
在TensorFlow 2官方文檔中也確認所需的CUDA版本:
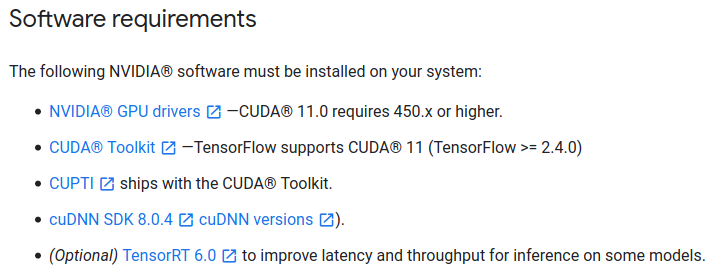
TensorFlow 2.4.0版本需要CUDA 11.0和cuDNN 8.0。
作者有時使用PyTorch,有時使用TensorFlow 2,所以確認了兩個套件都兼容的CUDA版本。你應該根據自己需要的套件要求來選擇。
5-2. 安裝CUDA
訪問CUDA Toolkit Archive,選擇前面確認的版本。本文選擇CUDA Toolkit 11.0 Update1:
選擇相應的平台和安裝程序類型,然後按照屏幕上的指示操作。建議盡可能使用系統套件管理器。作者偏好的方法是deb (network):
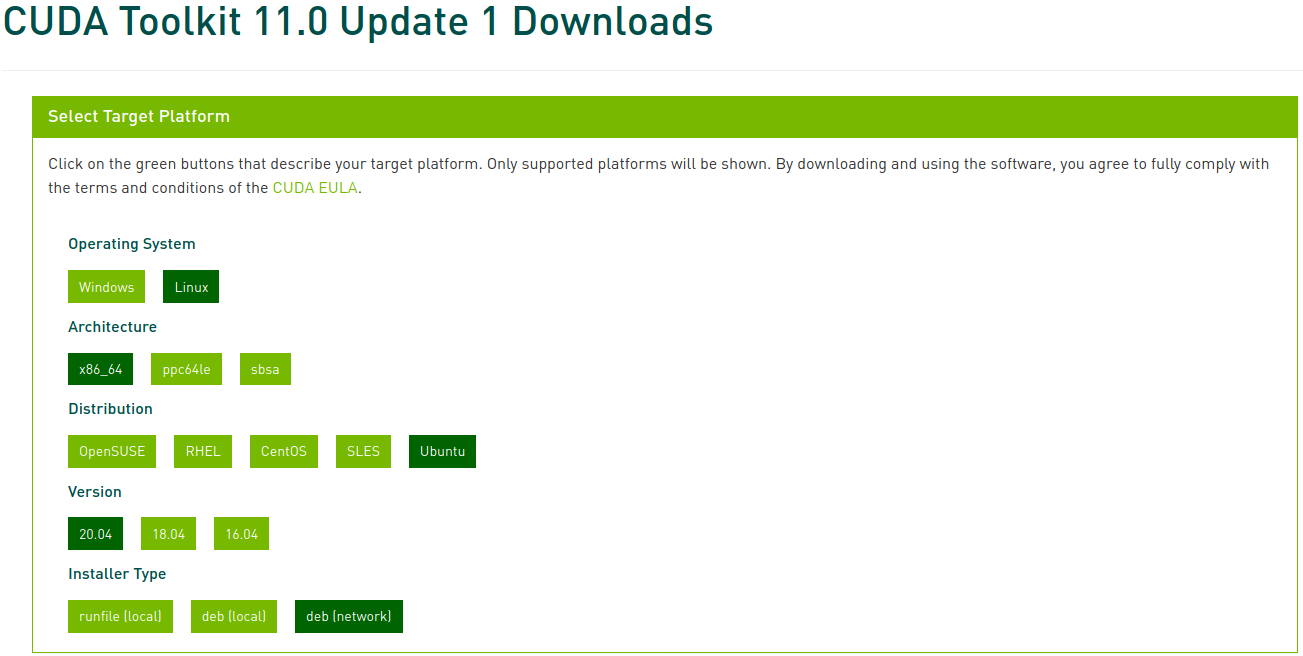
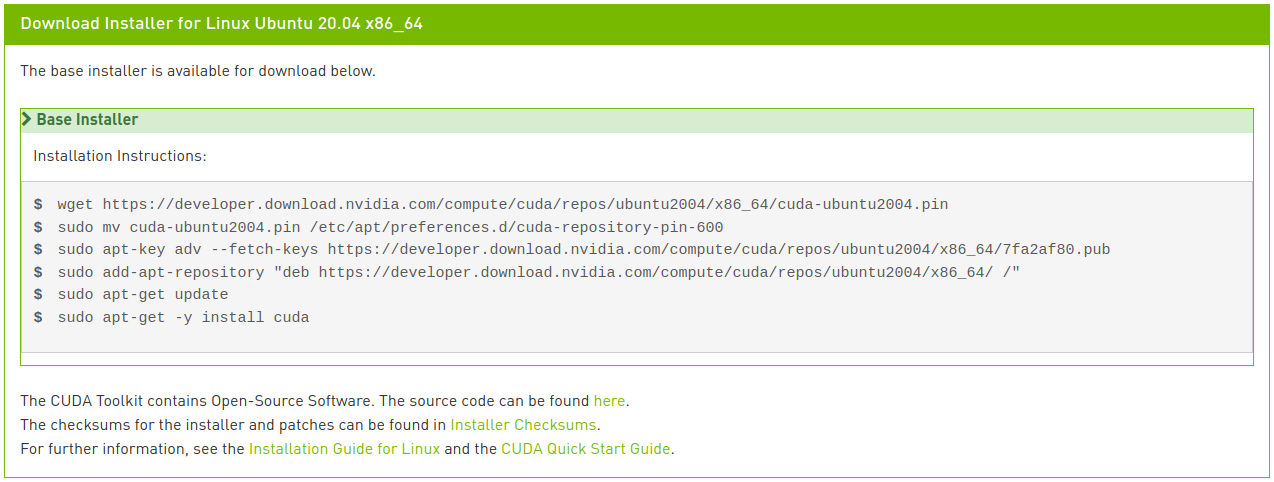
執行以下命令安裝CUDA:
1
2
3
4
5
6
$ wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/cuda-ubuntu2004.pin
$ sudo mv cuda-ubuntu2004.pin /etc/apt/preferences.d/cuda-repository-pin-600
$ sudo apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/7fa2af80.pub
$ sudo add-apt-repository "deb https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/ /"
$ sudo apt update
$ sudo apt install cuda-toolkit-11-0 cuda-drivers
如果你細心的話,會發現最後一行與圖片中的指示略有不同。在網絡安裝中,如果按照圖片輸入只有cuda,會安裝最新的11.2版本,這不是我們想要的。在CUDA 11.0 Linux安裝指南中可以查看各種元套件選項。這裡我們指定安裝CUDA Toolkit 11.0版本,並讓驅動程序套件自動升級,因此修改了最後一行。
5-3. 安裝cuDNN
按照以下方式安裝cuDNN:
1
2
$ sudo apt install libcudnn8=8.0.5.39-1+cuda11.0
$ sudo apt install libcudnn8-dev=8.0.5.39-1+cuda11.0
6. 安裝PyTorch
如果在第3步創建了虛擬環境,請確保在激活狀態下進行。如果不需要PyTorch,可以跳過此步驟。
訪問PyTorch網站,選擇要安裝的PyTorch版本(Stable)、操作系統(Linux)、套件(Pip)、語言(Python)和CUDA(11.0),然後按照屏幕上的指示操作:
1
(env) $ pip install torch==1.7.1+cu110 torchvision==0.8.2+cu110 torchaudio===0.7.2 -f https://download.pytorch.org/whl/torch_stable.html
要驗證PyTorch是否正確安裝,啟動Python解釋器並執行以下命令。如果返回張量,則安裝成功:
1
2
3
4
5
6
7
8
9
10
11
12
(env) $ python3
Python 3.8.5 (default, Jul 28 2020, 12:59:40)
[GCC 9.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
>>> x = torch.rand(5, 3)
>>> print(x)"
tensor([[0.8187, 0.5925, 0.2768],
[0.9884, 0.8298, 0.8553],
[0.6350, 0.7243, 0.2323],
[0.9205, 0.9239, 0.9065],
[0.2424, 0.1018, 0.3426]])
要確認GPU驅動和CUDA是否已激活並可用,執行以下命令:
1
2
>>> torch.cuda.is_available()
True
7. 安裝TensorFlow 2
如果不需要TensorFlow,可以忽略此步驟。
如果在第6步將PyTorch安裝到虛擬環境中,請停用該環境,返回第3、4步創建並激活新的虛擬環境後再繼續。如果跳過了第6步,則可以直接繼續。
按照以下方式安裝TensorFlow:
1
(env2) $ pip install --upgrade tensorflow
要驗證TensorFlow是否正確安裝,執行以下命令。如果顯示GPU名稱並返回張量,則安裝成功:
1
2
3
4
5
6
(env2) $ python -c "import tensorflow as tf;print(tf.reduce_sum(tf.random.normal([1000, 1000])))"
2021-02-07 22:45:51.390640: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0
(省略)
2021-02-07 22:45:54.592749: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1406] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 6878 MB memory) -> physical GPU (device: 0, name: GeForce RTX 3070, pci bus id: 0000:01:00.0, compute capability: 8.6)
tf.Tensor(526.1059, shape=(), dtype=float32)