Como traduzir posts automaticamente com a API Claude 3.5 Sonnet
Apresenta brevemente o modelo Claude 3.5 Sonnet recentemente lançado, compartilha o processo de design do prompt e o resultado final do prompt para aplicá-lo à tradução multilíngue dos posts deste blog. Também introduz como escrever e utilizar um script de automação de tradução em Python usando a chave de API obtida da Anthropic e o prompt escrito anteriormente.
Introdução
Recentemente, adotei a API Claude 3.5 Sonnet da Anthropic para tradução multilíngue dos posts do blog. Neste artigo, abordarei os motivos para escolher a API Claude 3.5 Sonnet, o método de design do prompt e como implementar a automação através da integração da API usando um script Python.
Sobre o Claude 3.5 Sonnet
Os modelos da série Claude 3 são fornecidos em versões Haiku, Sonnet e Opus, dependendo do tamanho do modelo.
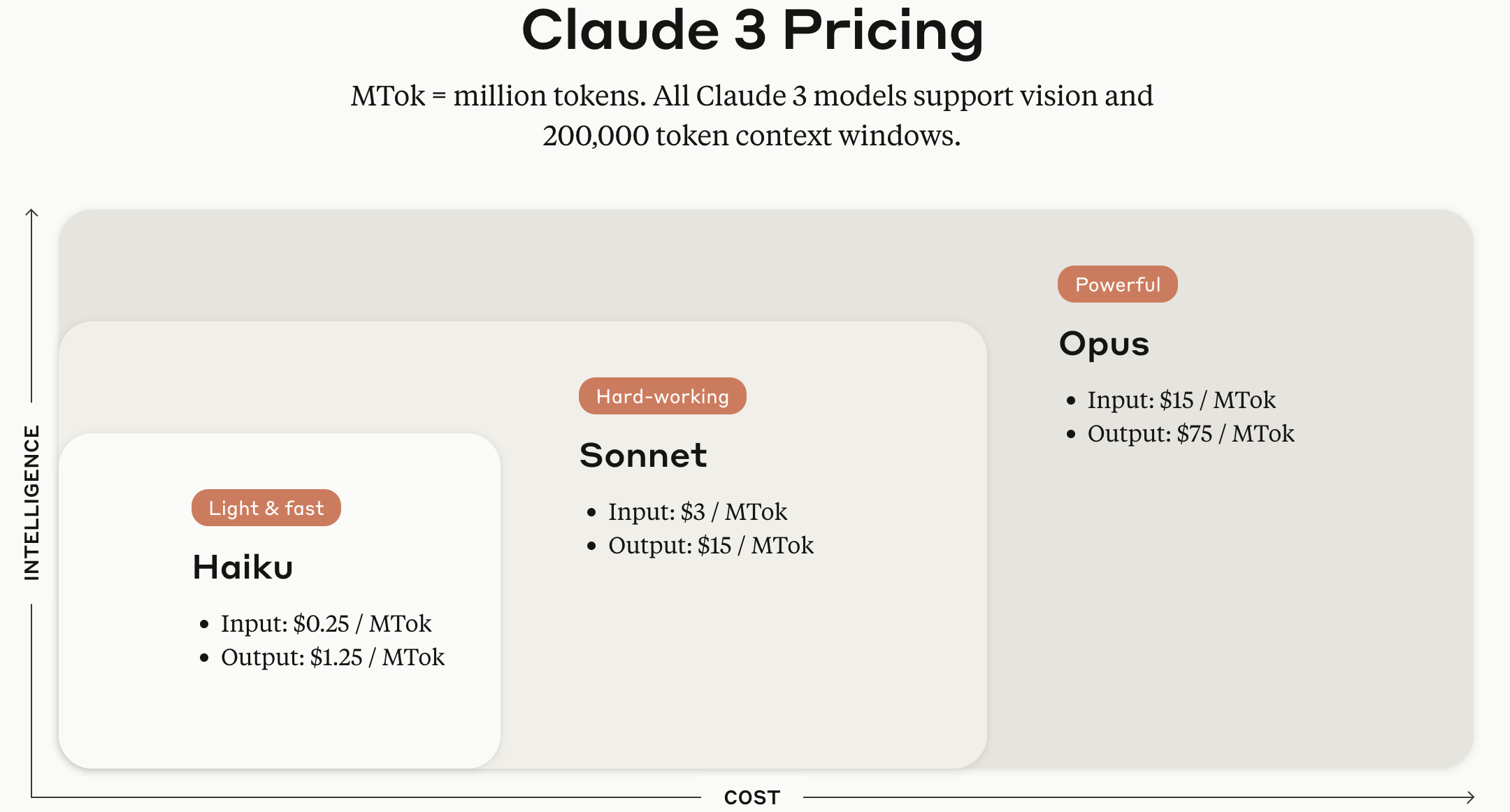
Fonte da imagem: Página oficial da API Claude da Anthropic
E no horário coreano de 21 de junho de 2024, a Anthropic lançou seu mais recente modelo de linguagem, o Claude 3.5 Sonnet. De acordo com o anúncio da Anthropic, ele supera o desempenho de inferência do Claude 3 Opus com o mesmo custo e velocidade do Claude 3 Sonnet existente, e geralmente é considerado superior ao modelo concorrente GPT-4 em áreas como redação, raciocínio linguístico, compreensão multilíngue e tradução.
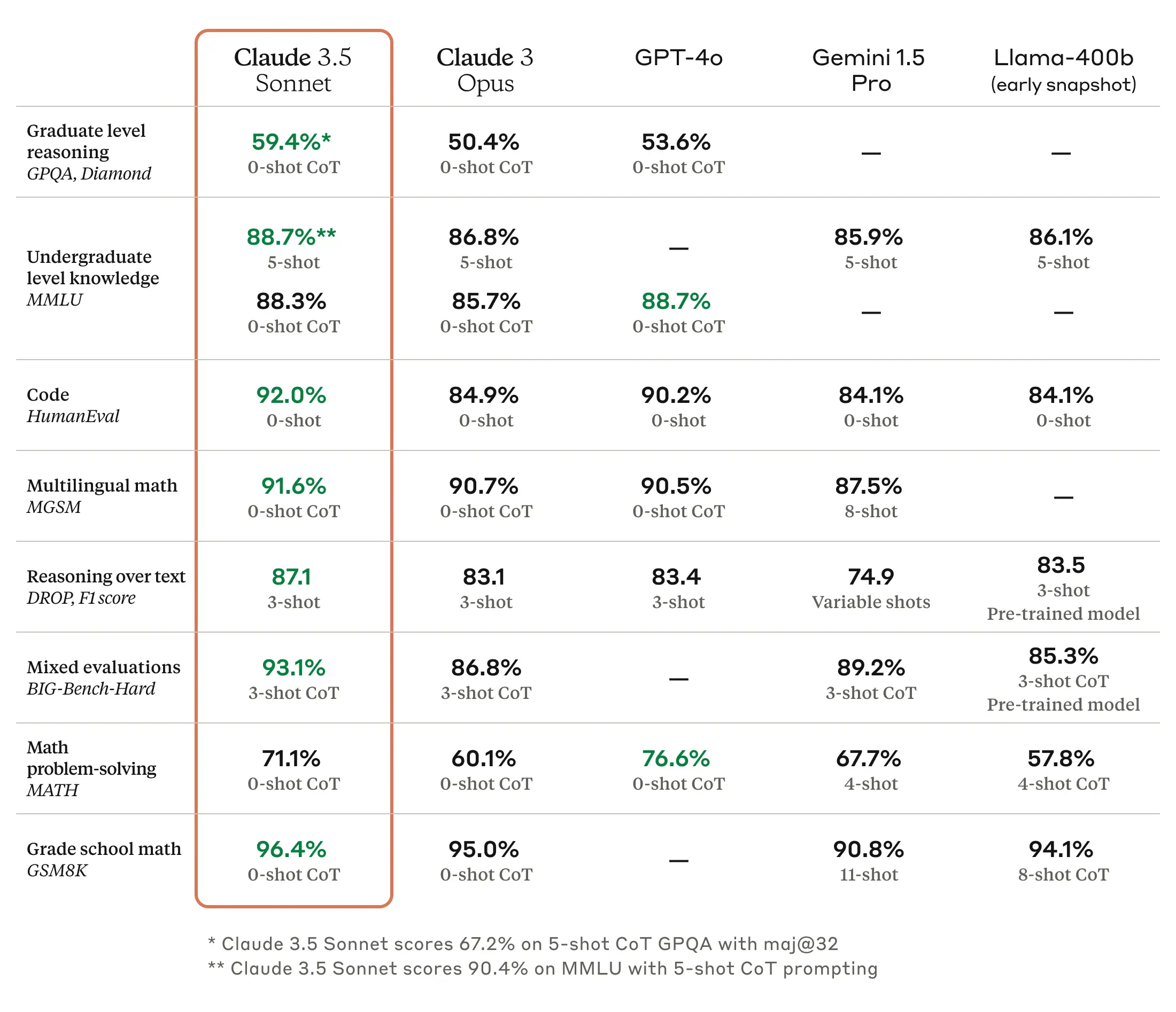
Fonte das imagens: Site da Anthropic
Motivos para adotar o Claude 3.5 para tradução de posts
Mesmo sem necessariamente usar modelos de linguagem como Claude 3.5 ou GPT-4, existem APIs de tradução comerciais existentes como Google Translate ou DeepL. A razão pela qual decidi usar um LLM para fins de tradução é que, diferentemente de outros serviços de tradução comerciais, o usuário pode fornecer informações contextuais adicionais ou requisitos além do texto principal, como o propósito de escrita ou os principais tópicos do texto, através do design do prompt, e o modelo pode fornecer uma tradução que considera o contexto de acordo com isso. Embora o DeepL e o Google Translate geralmente mostrem uma excelente qualidade de tradução, devido à limitação de não compreenderem bem o tema ou o contexto geral do texto, quando solicitados a traduzir textos longos sobre tópicos especializados, em vez de conversas cotidianas, os resultados da tradução tendem a ser relativamente não naturais. Especialmente, como mencionado anteriormente, o Claude é considerado relativamente superior ao modelo concorrente GPT-4 em áreas como redação, raciocínio linguístico, compreensão multilíngue e tradução, então julguei que seria adequado para a tarefa de traduzir os textos relacionados à engenharia escritos neste blog para vários idiomas.
Design do Prompt
Princípios básicos do design do prompt
Para obter resultados satisfatórios que atendam ao propósito de um modelo de linguagem, é necessário fornecer um prompt apropriado. O design do prompt pode parecer algo intimidante, mas na verdade, “como fazer um bom pedido” não é muito diferente se o interlocutor for um modelo de linguagem ou uma pessoa, então se você abordar com essa perspectiva, não é tão difícil. É bom explicar claramente a situação atual e os requisitos de acordo com os cinco Ws e um H, e adicionar alguns exemplos específicos, se necessário. Existem muitas dicas e técnicas para o design de prompts, mas a maioria delas deriva dos princípios básicos mencionados acima.
Atribuição de papel e explicação da situação (quem, por quê)
Primeiro, atribuí a Claude 3.5 o papel de “tradutor técnico profissional” e forneci informações contextuais sobre o usuário como “um blogueiro de engenharia que escreve principalmente sobre matemática, física e ciência de dados”.
You are a professional technical translator. Your client is an engineering blogger who writes mainly about math, physics (especially nuclear physics, quantum mechanics, and quantum information theory), and data science.
Transmissão dos requisitos gerais (o quê)
Em seguida, solicitei que traduzisse o texto em formato markdown fornecido pelo usuário de {source_lang} para {target_lang} mantendo o formato.
Translate the markdown-formatted text provided by the user from {source_lang} to {target_lang} while preserving the format.
Ao chamar a API Claude, as posições {source_lang} e {target_lang} no prompt são preenchidas com as variáveis de idioma de origem e destino, respectivamente, através da funcionalidade f-string do script Python.
Especificação de requisitos e exemplos (como)
Para tarefas simples, as etapas anteriores podem ser suficientes para obter os resultados desejados, mas para tarefas mais complexas, explicações adicionais podem ser necessárias. Neste caso, adicionei as seguintes condições:
Tratamento do YAML front matter
O YAML front matter localizado no início dos posts escritos em markdown para upload no blog Jekyll contém informações de ‘title’, ‘description’, ‘categories’ e ‘tags’. Por exemplo, o YAML front matter deste post é o seguinte:
---
title: Claude 3.5 Sonnet API로 포스트 자동 번역하는 법
description: >-
최근 공개된 Claude 3.5 Sonnet 모델을 간략히 소개하고, 본 블로그 포스트의 다국어 번역 작업에 적용하기 위해 프롬프트를 디자인한 과정과 완성한 프롬프트 결과물을 공유한다.
그리고 Anthropic으로부터 발급받은 API 키와 앞서 작성한 프롬프트를 적용하여 Python으로 번역 자동화 스크립트를 작성하고 활용하는 방법을 소개한다.
categories:
- Blogging
tags:
- Jekyll
- LLM
---
No entanto, ao traduzir os posts, as tags de título (title) e descrição (description) devem ser traduzidas para vários idiomas, mas para manter a consistência da URL do post, é mais fácil para a manutenção deixar os nomes das categorias (categories) e tags em inglês sem traduzir. Portanto, adicionei a seguinte instrução para não traduzir as tags além de ‘title’ e ‘description’. Como o Claude provavelmente já aprendeu sobre o YAML front matter, essa explicação deve ser suficiente na maioria dos casos.
In the provided markdown formatted text, do not translate the YAML front matter except for the ‘title’ and ‘description’ tags.
Tratamento de casos em que o texto original contém idiomas diferentes do idioma de origem
Ao escrever o texto original em coreano, às vezes, ao introduzir a definição de um conceito pela primeira vez ou usar alguns termos técnicos, é comum incluir a expressão em inglês entre parênteses, como ‘중성자 감쇠 (Neutron Attenuation)’. Ao traduzir essas expressões, havia um problema de inconsistência no método de tradução, às vezes mantendo os parênteses e outras vezes omitindo o inglês entre parênteses, então adicionei a seguinte frase ao prompt:
If the provided text contains language other than {source_lang}, please leave that part untouched. For example, ‘중성자 감쇠 (Neutron Attenuation)’ translates to ‘Neutron Attenuation’ in English and ‘Atténuation des neutrons (Neutron Attenuation)’ in French.
Tratamento de links para outros posts
Alguns posts incluem links para outros posts, e frequentemente ocorria o problema de links internos quebrarem porque a parte do caminho da URL era interpretada como algo que precisava ser traduzido e era alterada. Esse problema foi resolvido adicionando esta frase ao prompt:
Also, if the provided text contains links in markdown format, please translate the link text and the fragment part of the URL into {target_lang}, but keep the path part of the URL intact. For example, the German translation of ‘[중성자 상호작용과 반응단면적](/posts/Neutron-Interactions-and-Cross-sections/#단면적cross-section-또는-미시적-단면적microscopic-cross-section)’ would be ‘[Neutronenwechselwirkungen und Wirkungsquerschnitte](/posts/Neutron-Interactions-and-Cross-sections/#wirkungsquerschnitt-cross-section-oder-mikroskopischer-wirkungsquerschnitt-microscopic-cross-section)’.
Saída apenas do resultado da tradução como resposta
Por fim, apresenta-se a seguinte frase para produzir apenas o resultado da tradução como saída, sem adicionar outras palavras na resposta:
The output should only contain the translated text.
Prompt finalizado
O resultado do design do prompt após passar pelas etapas acima é o seguinte:
You are a professional technical translator. Your client is an engineering blogger who writes mainly about math, physics (especially nuclear physics, quantum mechanics, and quantum information theory), and data science. Translate the markdown-formatted text provided by the user from {source_lang} to {target_lang} while preserving the format. If the provided text contains language other than {source_lang}, please leave that part untouched. For example, ‘중성자 감쇠 (Neutron Attenuation)’ translates to ‘Neutron Attenuation’ in English and ‘Atténuation des neutrons (Neutron Attenuation)’ in French. Also, if the provided text contains links in markdown format, please translate the link text and the fragment part of the URL into {target_lang}, but keep the path part of the URL intact. For example, the German translation of ‘[중성자 상호작용과 반응단면적](/posts/Neutron-Interactions-and-Cross-sections/#단면적cross-section-또는-미시적-단면적microscopic-cross-section)’ would be ‘[Neutronenwechselwirkungen und Wirkungsquerschnitte](/posts/Neutron-Interactions-and-Cross-sections/#wirkungsquerschnitt-cross-section-oder-mikroskopischer-wirkungsquerschnitt-microscopic-cross-section)’. The output should only contain the translated text.
Integração da API Claude
Obtenção da chave da API Claude
Aqui, explicamos como obter uma nova chave da API Claude. Se você já possui uma chave de API para usar, pode pular esta etapa.
Acesse https://console.anthropic.com e faça login. Se você ainda não tem uma conta, primeiro precisa se registrar. Após fazer login, você verá uma tela de painel como a seguinte:
Clicando no botão ‘Get API keys’ nessa tela, você verá a seguinte tela:
 Como eu já tenho uma chave criada, uma chave chamada
Como eu já tenho uma chave criada, uma chave chamada yunseo-secret-key é exibida, mas se você acabou de criar sua conta e ainda não obteve uma chave de API, provavelmente não terá nenhuma chave. Você pode obter uma nova chave clicando no botão ‘Create Key’ no canto superior direito.
Quando você concluir a obtenção da chave, sua chave de API será exibida na tela, mas essa chave não poderá ser verificada novamente posteriormente, então certifique-se de registrá-la separadamente em um local seguro.
(Recomendado) Registro da chave da API Claude como variável de ambiente
Para usar a API Claude em scripts Python ou Shell, é necessário carregar a chave da API. Embora seja possível registrar a chave da API no próprio script, esse método não pode ser usado se o script precisar ser carregado no GitHub ou compartilhado com outras pessoas de outras maneiras. Além disso, mesmo que não houvesse intenção de compartilhar o arquivo do script, pode haver o risco de vazamento acidental do arquivo do script, e se a chave da API estiver registrada no arquivo do script, há o risco de vazamento da chave da API junto. Portanto, recomenda-se registrar a chave da API como uma variável de ambiente no sistema que apenas você usa e utilizar o método de carregar essa variável de ambiente no script. Abaixo, introduzimos o método de registrar a chave da API como uma variável de ambiente do sistema com base em sistemas UNIX. Para Windows, consulte outros artigos na web.
- No terminal, execute
nano ~/.bashrcounano ~/.zshrcde acordo com o tipo de shell que você usa para iniciar o editor. - Adicione
export ANTHROPIC_API_KEY='your-api-key-here'ao conteúdo do arquivo. Substitua ‘your-api-key-here’ pela sua chave de API, e observe que deve ser envolvida por aspas simples. - Salve as alterações e saia do editor.
- Execute
source ~/.bashrcousource ~/.zshrcno terminal para aplicar as alterações.
Instalação dos pacotes Python necessários
Se o pacote anthropic não estiver instalado no seu ambiente Python, instale-o com o seguinte comando:
1
pip3 install anthropic
Além disso, os seguintes pacotes também são necessários para usar o script de tradução de posts que será introduzido mais adiante, então instale ou atualize-os com o seguinte comando:
1
pip3 install -U argparse tqdm
Escrita do script Python
O script de tradução de posts que será introduzido neste artigo consiste em 3 arquivos de script Python e 1 arquivo CSV.
compare_hash.py: Calcula os valores de hash SHA256 dos posts originais em coreano no diretório_posts/koe compara com os valores de hash existentes registrados no arquivohash.csvpara retornar uma lista de nomes de arquivos alterados ou recentemente adicionadoshash.csv: Arquivo CSV que registra os valores de hash SHA256 dos arquivos de posts existentesprompt.py: Recebe os valores de filepath, source_lang, target_lang, carrega o valor da chave da API Claude da variável de ambiente do sistema, chama a API e submete o prompt escrito anteriormente como prompt do sistema e o conteúdo do post a ser traduzido em ‘filepath’ como prompt do usuário. Em seguida, recebe a resposta (resultado da tradução) do modelo Claude 3.5 Sonnet e a grava como um arquivo de texto no caminho'../_posts/' + language_code[target_lang] + '/' + filenametranslate_changes.py: Possui a variável de string source_lang e a lista ‘target_langs’, chama a funçãochanged_files()emcompare_hash.pypara retornar a lista de variáveis changed_files. Se houver arquivos alterados, executa um loop duplo para todos os arquivos na lista changed_files e todos os elementos na lista target_langs, e dentro desse loop, chama a funçãotranslate(filepath, source_lang, target_lang)emprompt.pypara realizar a tarefa de tradução.
O conteúdo dos arquivos de script completos também pode ser verificado no repositório GitHub yunseo-kim/yunseo-kim.github.io.
compare_hash.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
import os
import hashlib
import csv
def compute_file_hash(file_path):
sha256_hash = hashlib.sha256()
with open(file_path, "rb") as f:
for byte_block in iter(lambda: f.read(4096), b""):
sha256_hash.update(byte_block)
return sha256_hash.hexdigest()
def load_existing_hashes(csv_path):
existing_hashes = {}
if os.path.exists(csv_path):
with open(csv_path, 'r') as csvfile:
reader = csv.reader(csvfile)
for row in reader:
if len(row) == 2:
existing_hashes[row[0]] = row[1]
return existing_hashes
def update_hash_csv(csv_path, file_hashes):
with open(csv_path, 'w', newline='') as csvfile:
writer = csv.writer(csvfile)
for file_path, hash_value in file_hashes.items():
writer.writerow([file_path, hash_value])
def changed_files():
posts_dir = '../_posts/ko/'
hash_csv_path = './hash.csv'
existing_hashes = load_existing_hashes(hash_csv_path)
current_hashes = {}
changed_files = []
for root, _, files in os.walk(posts_dir):
for file in files:
file_path = os.path.join(root, file)
relative_path = os.path.relpath(file_path, start=posts_dir)
current_hash = compute_file_hash(file_path)
current_hashes[relative_path] = current_hash
if relative_path in existing_hashes:
if current_hash != existing_hashes[relative_path]:
changed_files.append(relative_path)
else:
changed_files.append(relative_path)
update_hash_csv(hash_csv_path, current_hashes)
if __name__ == "__main__":
if changed_files:
print("Changed files:")
for file in changed_files:
print(f"- {file}")
else:
print("No files have changed.")
return changed_files
prompt.py
Como inclui o conteúdo do prompt escrito anteriormente, o conteúdo do arquivo é um pouco longo, então é substituído pelo link do arquivo fonte no repositório GitHub.
https://github.com/yunseo-kim/yunseo-kim.github.io/blob/main/tools/prompt.py
No arquivo
prompt.pyno link acima,max_tokensé uma variável que especifica o comprimento máximo de saída separadamente do tamanho da janela de contexto. Ao usar a API Claude, o tamanho da janela de contexto que pode ser inserido de uma vez é de 200k tokens (cerca de 680.000 caracteres), mas separadamente disso, cada modelo tem um número máximo de tokens de saída suportado, então é recomendado verificar antecipadamente na documentação oficial da Anthropic antes de usar a API. Os modelos da série Claude 3 existentes podiam produzir até 4096 tokens, e embora não houvesse problemas na maioria dos posts deste blog nos experimentos, para alguns posts com conteúdo mais longo, com cerca de 8000 caracteres em coreano, ocorreu o problema de corte da parte final da tradução em alguns idiomas de saída, excedendo 4096 tokens. No caso do Claude 3.5 Sonnet, o número máximo de tokens de saída dobrou para 8192, então não houve problemas excedendo esse número máximo de tokens de saída na maioria dos casos, e noprompt.pyno repositório GitHub acima, também foi especificadomax_tokens=8192.
translate_changes.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
import sys
import os
from tqdm import tqdm
import compare_hash
import prompt
posts_dir = '../_posts/ko/'
source_lang = "Korean"
target_langs = ["English", "Spanish", "Brazilian Portuguese", "Japanese", "French", "German"]
if __name__ == "__main__":
changed_files = compare_hash.changed_files()
if not changed_files:
sys.exit("No files have changed.")
print("Changed files:")
for file in changed_files:
print(f"- {file}")
print("")
print("*** Translation start! ***")
for changed_file in changed_files:
print(f"- Translating {changed_file}")
filepath = os.path.join(posts_dir, changed_file)
for target_lang in tqdm(target_langs):
prompt.translate(filepath, source_lang, target_lang)
Como usar o script Python
Com base no blog Jekyll, coloque subdiretórios como /_posts/ko, /_posts/en, /_posts/pt-BR dentro do diretório /_posts onde os posts estão localizados, de acordo com os códigos de idioma ISO 639-1. Em seguida, coloque os scripts Python e o arquivo CSV introduzidos acima no diretório /tools, abra um terminal nessa localização e execute o seguinte comando:
1
python3 translate_changes.py
Então o script será executado e uma tela como a seguinte será exibida:
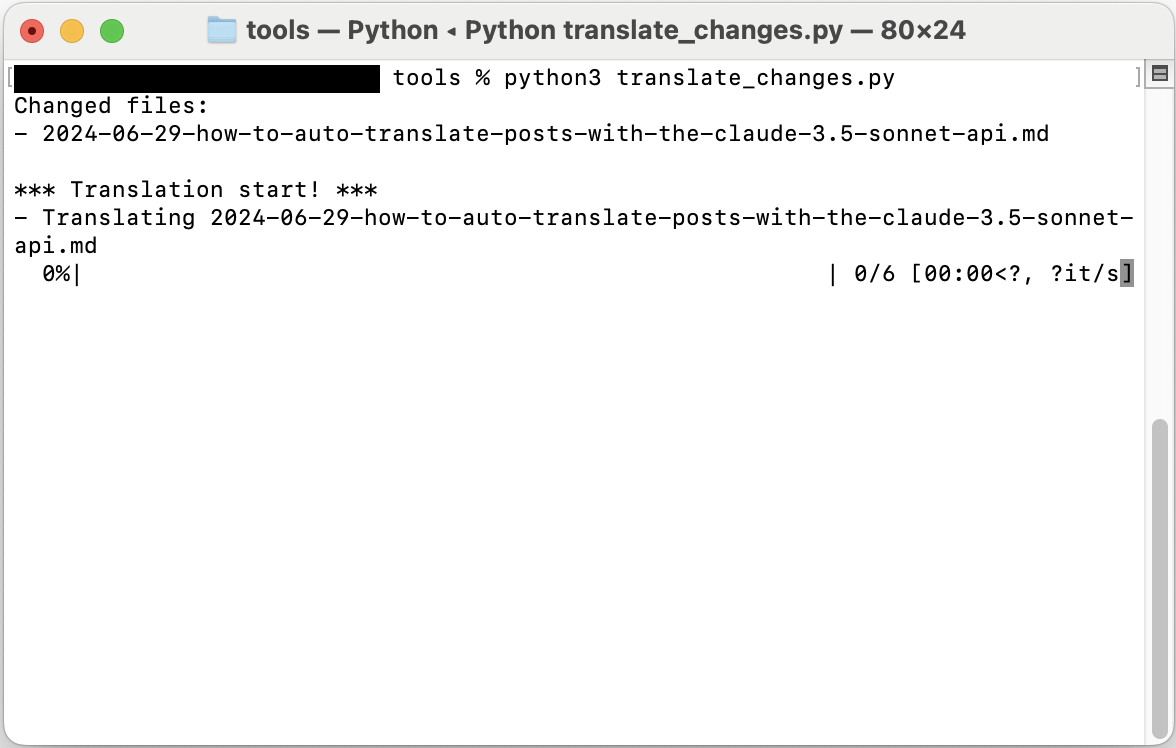
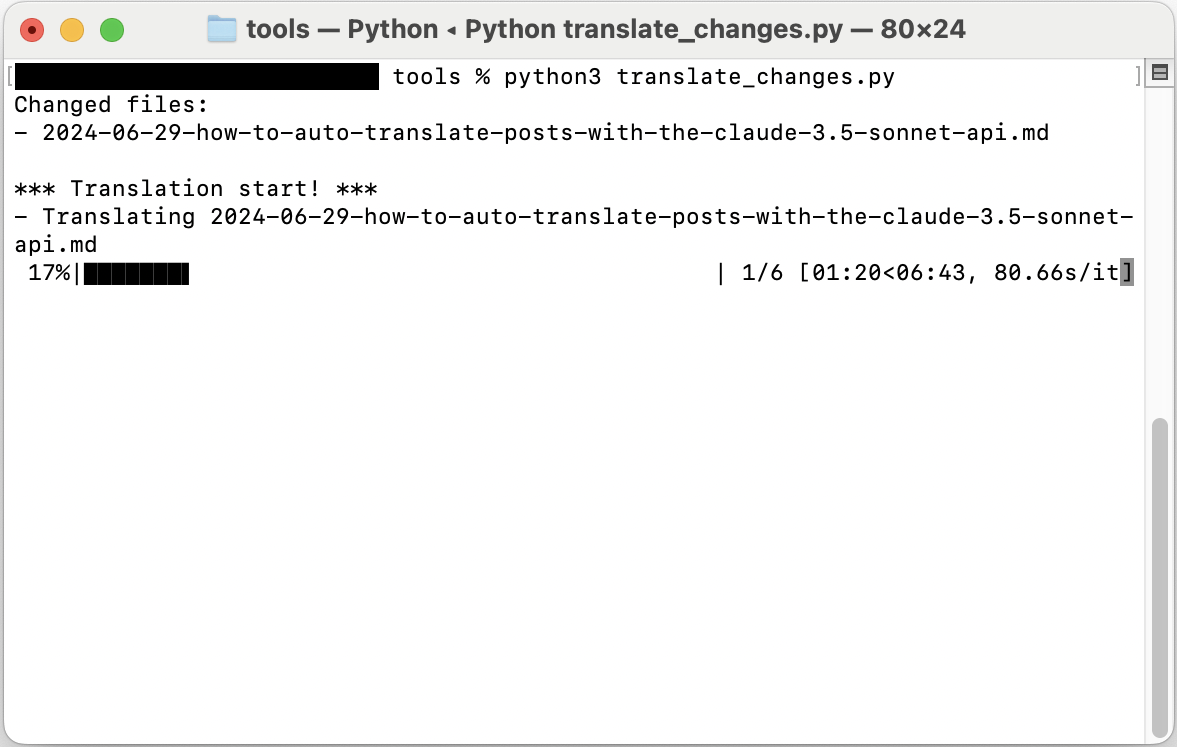
Experiência de uso real
Como mencionado acima, estou usando a tradução automática de posts usando a API Claude 3.5 neste blog há cerca de 2 meses. Na maioria dos casos, é possível receber traduções de excelente qualidade sem a necessidade de intervenção humana adicional, e após postar as traduções multilíngues dos posts, confirmei que o tráfego de Organic Search através de pesquisas de regiões fora da Coreia, como Brasil, Canadá, Estados Unidos e França, está realmente chegando. Além do tráfego do blog, também houve vantagens adicionais em termos de aprendizado para o autor do texto, pois como o Claude produz textos bastante fluentes em inglês, durante o processo de revisão antes de fazer o Push dos posts para o repositório do GitHub Pages, há a oportunidade de verificar como certos termos ou expressões que escrevi no texto original em coreano são naturalmente expressos em inglês. Embora isso por si só não seja suficiente para um aprendizado completo de inglês, para um estudante de graduação em engenharia de um país não anglófono como a Coreia, parece ser uma vantagem considerável poder frequentemente encontrar expressões naturais em inglês não apenas para expressões cotidianas, mas também para expressões e termos acadêmicos, usando como exemplo o texto que eu mesmo escrevi, que é mais familiar do que qualquer outro texto, sem nenhum esforço adicional.
Comments powered by Disqus.