Construindo um ambiente de desenvolvimento para Machine Learning
Este artigo aborda como configurar um ambiente de desenvolvimento, que pode ser considerado o primeiro passo para estudar machine learning em uma máquina local. Todo o conteúdo foi escrito com base no Ubuntu 20.04 LTS com uma placa gráfica NVIDIA Geforce RTX 3070.
Visão Geral
Este artigo aborda como configurar um ambiente de desenvolvimento, que pode ser considerado o primeiro passo para estudar machine learning em uma máquina local. Todo o conteúdo foi escrito com base no Ubuntu 20.04 LTS com uma placa gráfica NVIDIA Geforce RTX 3070.
- Stack tecnológico a ser configurado
- Ubuntu 20.04 LTS
- Python 3.8
- pip 21.0.1
- jupyter
- matplotlib
- numpy
- pandas
- scipy
- scikit-learn
- CUDA 11.0.3
- cuDNN 8.0.5
- Frameworks de Deep Learning (recomenda-se instalar apenas um por ambiente)
- PyTorch 1.7.1
- TensorFlow 2.4.0
Tabela comparativa com o novo guia de configuração de ambiente para Machine Learning
Embora tenha se passado cerca de 3 anos e meio desde que este artigo foi publicado no blog, seu conteúdo ainda é válido em linhas gerais, exceto por alguns detalhes específicos como versões de pacotes e o lançamento de drivers de código aberto da NVIDIA. No entanto, ao comprar um novo PC e configurar um ambiente de desenvolvimento no verão de 12024 do calendário holoceno, houve algumas mudanças que me levaram a escrever um novo guia de configuração de ambiente. As diferenças são mostradas na tabela abaixo.
| Diferença | Este artigo (versão 12021) | Novo artigo (versão 12024) |
|---|---|---|
| Distribuição Linux | Baseado em Ubuntu | Aplicável também a Fedora/RHEL/Centos, Debian, openSUSE/SLES, além do Ubuntu |
| Método de configuração | Ambiente virtual Python usando venv | Ambiente baseado em contêineres Docker usando NVIDIA Container Toolkit |
| Instalação de drivers gráficos NVIDIA | Sim | Sim |
| Instalação direta de CUDA e cuDNN no sistema host | Sim (usando gerenciador de pacotes Apt) | Não (usa imagens pré-instaladas fornecidas pela NVIDIA no Docker Hub, eliminando a necessidade de instalação manual) |
| Portabilidade | Necessário reconstruir o ambiente ao migrar para outro sistema | Baseado em Docker, permitindo construir novas imagens a partir do Dockerfile existente ou portar facilmente imagens existentes (excluindo configurações adicionais de volume ou rede) |
| Uso de bibliotecas de aceleração GPU adicionais além do cuDNN | Não | Introdução de CuPy, cuDF, cuML, DALI |
| Interface Jupyter Notebook | Jupyter Notebook (clássico) | JupyterLab (próxima geração) |
| Configuração de servidor SSH | Não abordado | Inclui configuração básica de servidor SSH na parte 3 |
Se você preferir usar ambientes virtuais Python como venv em vez de Docker, este artigo original ainda é válido e você pode continuar lendo. Se quiser aproveitar as vantagens dos contêineres Docker, como alta portabilidade, ou planeja usar outras distribuições Linux além do Ubuntu, ou tem uma placa gráfica NVIDIA e deseja utilizar bibliotecas adicionais de aceleração GPU como CuPy, cuDF, cuML e DALI, ou deseja configurar acesso remoto via SSH e JupyterLab, recomendo consultar também o novo guia.
0. Pré-requisitos
- Para estudar machine learning, recomenda-se usar Linux. Embora seja possível no Windows, você pode perder muito tempo com pequenos problemas. Usar a versão LTS mais recente do Ubuntu é a opção mais segura. É conveniente porque drivers proprietários são instalados automaticamente, e como tem muitos usuários, a maioria da documentação técnica é escrita com base no Ubuntu.
- Geralmente, o Python já vem pré-instalado na maioria das distribuições Linux, incluindo o Ubuntu. No entanto, se o Python não estiver instalado, você precisará instalá-lo antes de seguir este guia.
- Você pode verificar a versão atual do Python com o seguinte comando:
1
$ python3 --version
- Se você planeja usar TensorFlow 2 ou PyTorch, deve verificar as versões compatíveis do Python. No momento da escrita deste artigo, a versão mais recente do PyTorch suporta Python 3.6-3.8, e a versão mais recente do TensorFlow 2 suporta Python 3.5-3.8.
Neste artigo, usaremos Python 3.8.
- Você pode verificar a versão atual do Python com o seguinte comando:
- Se você planeja estudar machine learning em sua máquina local, é recomendável ter pelo menos uma GPU. Embora o pré-processamento de dados possa ser feito com CPU, a diferença de velocidade entre CPU e GPU durante o treinamento de modelos é enorme à medida que os modelos crescem (especialmente para deep learning).
- Para machine learning, a escolha de fabricante de GPU é praticamente única: você deve usar produtos NVIDIA. A NVIDIA investiu significativamente no campo de machine learning, e quase todos os frameworks de machine learning usam a biblioteca CUDA da NVIDIA.
- Se você planeja usar GPU para machine learning, primeiro verifique se seu modelo de placa gráfica suporta CUDA. Você pode verificar o modelo da GPU instalada em seu computador usando o comando
uname -m && cat /etc/*releaseno terminal. Encontre o modelo correspondente na lista de GPUs neste link e verifique o valor de Compute Capability. Este valor deve ser pelo menos 3.5 para suportar CUDA. - Os critérios para seleção de GPU estão bem resumidos no seguinte artigo, que o autor atualiza continuamente:
Which GPU(s) to Get for Deep Learning
Outro artigo muito útil do mesmo autor é A Full Hardware Guide to Deep Learning. A conclusão desses artigos é:The RTX 3070 and RTX 3080 are mighty cards, but they lack a bit of memory. For many tasks, however, you do not need that amount of memory.
The RTX 3070 is perfect if you want to learn deep learning. This is so because the basic skills of training most architectures can be learned by just scaling them down a bit or using a bit smaller input images. If I would learn deep learning again, I would probably roll with one RTX 3070, or even multiple if I have the money to spare. The RTX 3080 is currently by far the most cost-efficient card and thus ideal for prototyping. For prototyping, you want the largest memory, which is still cheap. With prototyping, I mean here prototyping in any area: Research, competitive Kaggle, hacking ideas/models for a startup, experimenting with research code. For all these applications, the RTX 3080 is the best GPU.
Se você atender a todos os requisitos mencionados acima, vamos começar a configurar o ambiente de trabalho.
1. Criando o diretório de trabalho
Abra o terminal e modifique o arquivo .bashrc para registrar variáveis de ambiente (os comandos seguem após o prompt $).
Primeiro, abra o editor nano com o seguinte comando (você pode usar vim ou outro editor, se preferir):
1
$ nano ~/.bashrc
Adicione o seguinte conteúdo na última linha. Você pode alterar o caminho entre aspas duplas, se desejar:
export ML_PATH="$HOME/ml"
Pressione Ctrl+O para salvar e Ctrl+X para sair.
Agora execute o seguinte comando para aplicar a variável de ambiente:
1
$ source ~/.bashrc
Crie o diretório:
1
$ mkdir -p $ML_PATH
2. Instalando o gerenciador de pacotes pip
Existem várias maneiras de instalar os pacotes Python necessários para machine learning. Você pode usar distribuições científicas Python como Anaconda (recomendado para Windows) ou usar o pip, a ferramenta de empacotamento nativa do Python. Aqui, usaremos o comando pip no shell bash do Linux ou macOS.
Verifique se o pip está instalado em seu sistema com o seguinte comando:
1
2
3
4
5
6
$ pip3 --version
Comando 'pip3' não encontrado, mas pode ser instalado com:
sudo apt install python3-pip
Se você ver algo como acima, o pip não está instalado em seu sistema. Instale-o usando o gerenciador de pacotes do sistema (neste caso, apt). Se uma versão for exibida, o pip já está instalado e você pode pular este comando.
1
$ sudo apt install python3-pip
Agora o pip está instalado em seu sistema.
3. Criando um ambiente virtual independente (recomendado)
Para criar um ambiente virtual (para evitar conflitos de versões de bibliotecas com outros projetos), instale o venv:
1
$ sudo apt install python3-venv
Em seguida, crie um ambiente Python independente da seguinte forma. Isso é feito para evitar conflitos entre versões de bibliotecas necessárias para diferentes projetos, então você deve criar um novo ambiente virtual para cada novo projeto.
1
2
$ cd $ML_PATH
$ python3 -m venv --system-site-packages ./(nome do ambiente)
Para ativar este ambiente virtual, abra um terminal e digite:
1
2
$ cd $ML_PATH
$ source ./(nome do ambiente)/bin/activate
Após ativar o ambiente virtual, atualize o pip dentro do ambiente:
1
(env) $ pip install -U pip
Para desativar o ambiente virtual posteriormente, use o comando deactivate. Quando o ambiente está ativado, qualquer pacote instalado com o comando pip será instalado neste ambiente isolado, e o Python usará esses pacotes.
3′. (Se não criar um ambiente virtual) Atualizando a versão do pip
Quando você instala o pip no sistema, ele baixa e instala um arquivo binário do servidor espelho da distribuição (neste caso, Ubuntu), que geralmente não é a versão mais recente devido a atualizações lentas (no meu caso, a versão 20.3.4 foi instalada). Para usar a versão mais recente do pip, execute o seguinte comando para instalar (ou atualizar, se já estiver instalado) o pip no diretório home do usuário:
1
2
3
4
5
$ python3 -m pip install -U pip
Collecting pip
(resumido)
Successfully installed pip-21.0.1
Você pode ver que o pip foi instalado na versão 21.0.1, a mais recente no momento da escrita deste artigo. Como o pip instalado no diretório home do usuário não é automaticamente reconhecido pelo sistema, você precisa registrá-lo na variável de ambiente PATH para que o sistema possa reconhecê-lo e usá-lo.
Abra novamente o arquivo .bashrc com um editor:
1
$ nano ~/.bashrc
Desta vez, procure a linha que começa com export PATH=. Se não houver caminhos listados após isso, basta adicionar o conteúdo como fizemos na etapa 1. Se já existirem outros caminhos registrados, adicione o novo caminho após eles, separado por dois pontos:
export PATH="$HOME/.local/bin"
export PATH="(caminho existente):$HOME/.local/bin"
Atualizar o pip do sistema por métodos diferentes do gerenciador de pacotes do sistema pode causar problemas devido a conflitos de versão. É por isso que instalamos o pip separadamente no diretório home do usuário. Pela mesma razão, é recomendável usar o comando python3 -m pip em vez de pip quando não estiver em um ambiente virtual.
4. Instalando pacotes para machine learning (jupyter, matplotlib, numpy, pandas, scipy, scikit-learn)
Instale todos os pacotes necessários e suas dependências com o seguinte comando pip:
Como estou usando venv, uso simplesmente o comando pip, mas se você não estiver usando venv, recomendo usar o comando python3 -m pip como mencionado anteriormente.
1
2
3
4
5
6
(env) $ pip install -U jupyter matplotlib numpy pandas scipy scikit-learn
Collecting jupyter
Downloading jupyter-1.0.0-py2.py3-none-any.whl (2.7 kB)
Collecting matplotlib
(resumido)
Se você estiver usando venv, registre um kernel no Jupyter e dê-lhe um nome:
1
(env) $ python3 -m ipykernel install --user --name=(nome do kernel)
Agora você pode executar o Jupyter com o seguinte comando:
1
(env) $ jupyter notebook
5. Instalando CUDA & cuDNN
5-1. Verificando as versões necessárias de CUDA & cuDNN
Verifique as versões de CUDA suportadas na documentação oficial do PyTorch:

Para o PyTorch 1.7.1, as versões de CUDA suportadas são 9.2, 10.1, 10.2 e 11.0. Como as GPUs NVIDIA série 30 requerem CUDA 11, sabemos que precisamos da versão 11.0.
Verifique também as versões necessárias na documentação oficial do TensorFlow 2:
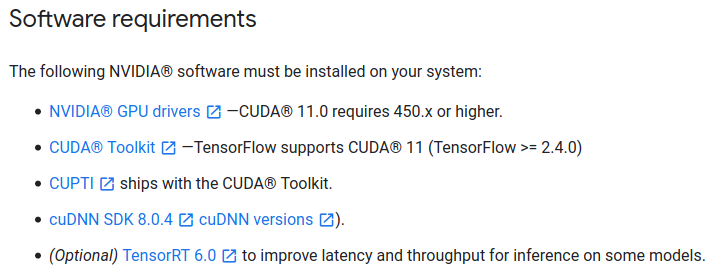
Para o TensorFlow 2.4.0, também precisamos da versão 11.0 do CUDA e da versão 8.0 do cuDNN.
Como uso tanto PyTorch quanto TensorFlow 2 dependendo da situação, verifiquei versões de CUDA compatíveis com ambos os pacotes. Você deve verificar os requisitos dos pacotes que precisa e ajustar de acordo.
5-2. Instalando CUDA
Acesse o CUDA Toolkit Archive e selecione a versão que você verificou anteriormente. Neste artigo, selecionamos CUDA Toolkit 11.0 Update1:
Agora selecione a plataforma e o tipo de instalador correspondentes, e siga as instruções na tela. É recomendável usar o gerenciador de pacotes do sistema para o instalador. Meu método preferido é deb (network):
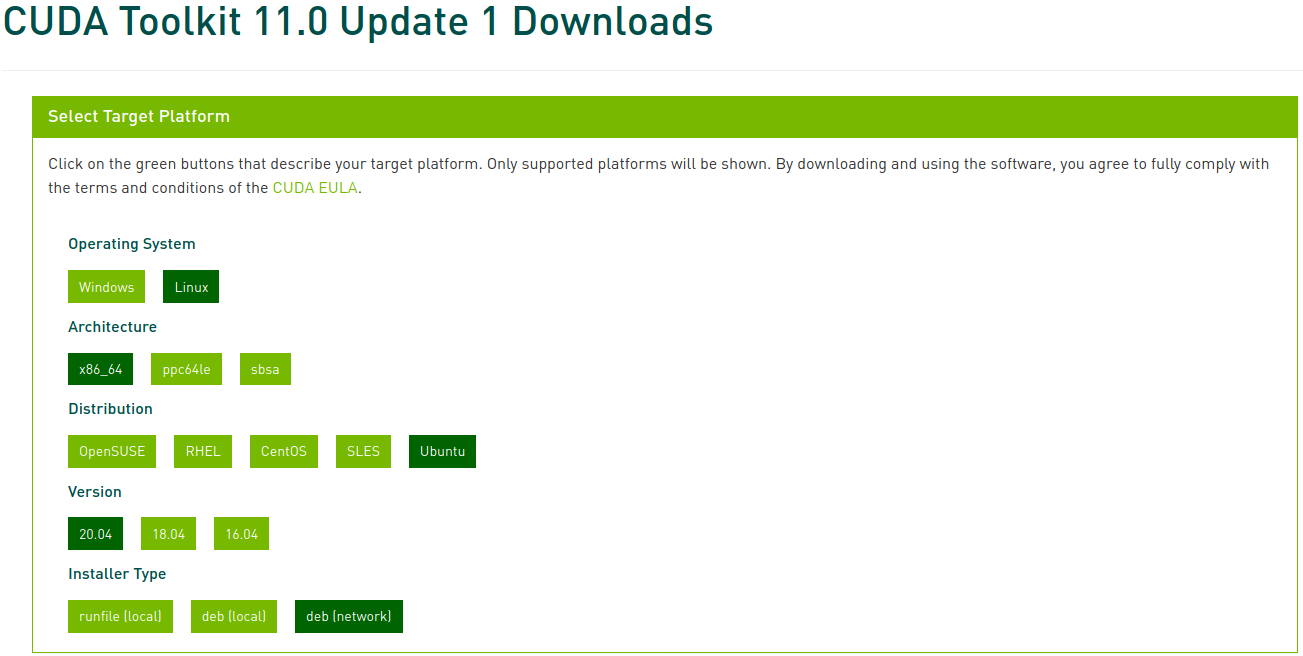
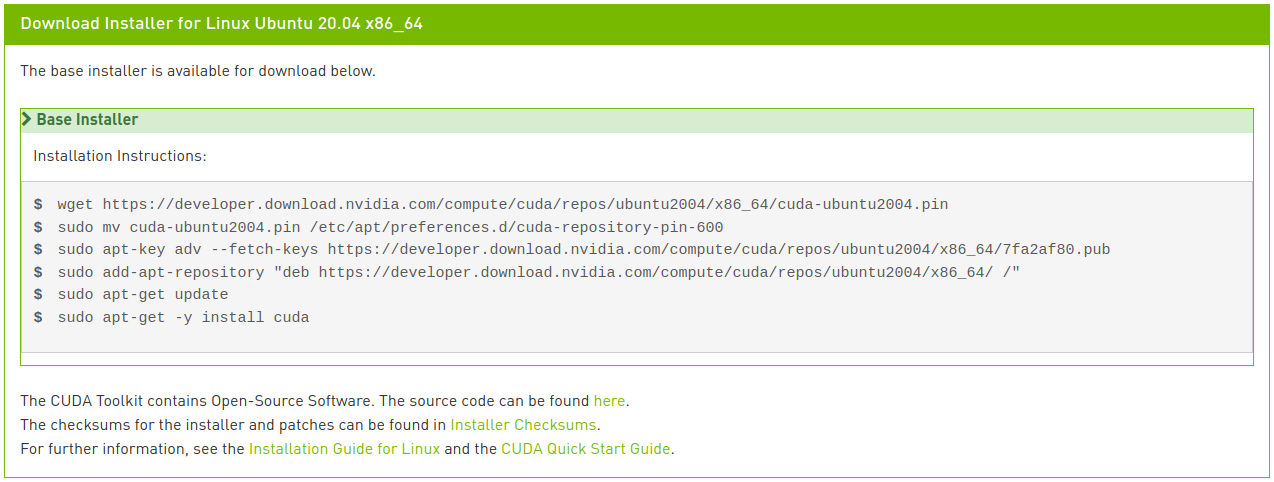
Execute os seguintes comandos para instalar o CUDA:
1
2
3
4
5
6
$ wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/cuda-ubuntu2004.pin
$ sudo mv cuda-ubuntu2004.pin /etc/apt/preferences.d/cuda-repository-pin-600
$ sudo apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/7fa2af80.pub
$ sudo add-apt-repository "deb https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/ /"
$ sudo apt update
$ sudo apt install cuda-toolkit-11-0 cuda-drivers
Se você for observador, notará que a última linha é ligeiramente diferente das instruções mostradas na imagem. Na instalação via rede, se você digitar apenas “cuda” como mostrado na imagem, a versão mais recente (11.2) será instalada, o que não é o que queremos. Você pode ver várias opções de meta-pacotes no Guia de Instalação do CUDA 11.0 para Linux. Modificamos a última linha para especificar a instalação do CUDA Toolkit versão 11.0, permitindo que o pacote de drivers seja atualizado automaticamente.
5-3. Instalando cuDNN
Instale o cuDNN da seguinte forma:
1
2
$ sudo apt install libcudnn8=8.0.5.39-1+cuda11.0
$ sudo apt install libcudnn8-dev=8.0.5.39-1+cuda11.0
6. Instalando PyTorch
Se você criou um ambiente virtual na etapa 3, continue com esse ambiente ativado. Pule esta etapa se não precisar do PyTorch.
Acesse o site do PyTorch, selecione a versão do PyTorch (Stable), sistema operacional (Linux), pacote (Pip), linguagem (Python), CUDA (11.0) e siga as instruções na tela:
1
(env) $ pip install torch==1.7.1+cu110 torchvision==0.8.2+cu110 torchaudio===0.7.2 -f https://download.pytorch.org/whl/torch_stable.html
Para verificar se o PyTorch foi instalado corretamente, execute o interpretador Python e os seguintes comandos. Se um tensor for retornado, a instalação foi bem-sucedida:
1
2
3
4
5
6
7
8
9
10
11
12
(env) $ python3
Python 3.8.5 (default, Jul 28 2020, 12:59:40)
[GCC 9.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
>>> x = torch.rand(5, 3)
>>> print(x)"
tensor([[0.8187, 0.5925, 0.2768],
[0.9884, 0.8298, 0.8553],
[0.6350, 0.7243, 0.2323],
[0.9205, 0.9239, 0.9065],
[0.2424, 0.1018, 0.3426]])
Para verificar se o driver GPU e o CUDA estão ativos e disponíveis, execute o seguinte comando:
1
2
>>> torch.cuda.is_available()
True
7. Instalando TensorFlow 2
Ignore esta etapa se você não precisar do TensorFlow.
Se você instalou o PyTorch em um ambiente virtual na etapa 6, desative esse ambiente e volte às etapas 3 e 4 para criar e ativar um novo ambiente virtual antes de continuar. Se você pulou a etapa 6, continue normalmente.
Instale o TensorFlow da seguinte forma:
1
(env2) $ pip install --upgrade tensorflow
Para verificar se o TensorFlow foi instalado corretamente, execute o seguinte comando. Se ele exibir o nome da GPU e retornar um tensor, a instalação foi bem-sucedida:
1
2
3
4
5
6
(env2) $ python -c "import tensorflow as tf;print(tf.reduce_sum(tf.random.normal([1000, 1000])))"
2021-02-07 22:45:51.390640: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0
(resumido)
2021-02-07 22:45:54.592749: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1406] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 6878 MB memory) -> physical GPU (device: 0, name: GeForce RTX 3070, pci bus id: 0000:01:00.0, compute capability: 8.6)
tf.Tensor(526.1059, shape=(), dtype=float32)