머신러닝 개발환경 구축하기
이 글에서는 로컬 머신에서 머신러닝을 공부하기 위한 첫 단계라고 할 수 있는 개발환경 구축 방법에 대해 다룬다. 모든 내용은 우분투 20.04 LTS상에서 NVIDIA Geforce RTX 3070 그래픽카드를 기준으로 작성하였다.
개요
이 글에서는 로컬 머신에서 머신러닝을 공부하기 위한 첫 단계라고 할 수 있는 개발환경 구축 방법에 대해 다룬다. 모든 내용은 우분투 20.04 LTS상에서 NVIDIA Geforce RTX 3070 그래픽카드를 기준으로 작성하였다.
- 구축할 기술 스택
- Ubuntu 20.04 LTS
- Python 3.8
- pip 21.0.1
- jupyter
- matplotlib
- numpy
- pandas
- scipy
- scikit-learn
- CUDA 11.0.3
- cuDNN 8.0.5
- 딥러닝 프레임워크(각 환경당 하나만 선택하여 설치하는 것을 권장)
- PyTorch 1.7.1
- TensorFlow 2.4.0
새로 작성한 머신러닝 개발환경 구축 가이드와의 비교표
비록 블로그에 업로드한지 3년 반 정도가 지났지만, 여전히 이 글의 내용은 패키지 버전이나 NVIDIA 오픈소스 드라이버 발표 등의 몇몇 세부적인 부분을 제외하면 큰 틀에서는 유효하다. 그러나 인류력 12024년 여름에 새로운 PC를 구입하고 개발환경을 구축하면서 몇 가지 변경점이 있어 새로운 개발환경 구축 가이드를 작성하였다. 달라진 점들은 아래 표와 같다.
| 차이점 | 본문 (12021 버전) | 새로운 글 (12024 버전) |
|---|---|---|
| 리눅스 배포판 | Ubuntu 기준 | Ubuntu 외에도 Fedora/RHEL/Centos, Debian, openSUSE/SLES 등에서 적용 가능 |
| 개발환경 구축 방식 | venv를 이용한 파이썬 가상환경 | NVIDIA Container Toolkit을 이용한 Docker 컨테이너 기반 환경 |
| NVIDIA 그래픽 드라이버 설치 | O | O |
| 호스트 시스템에 CUDA 및 cuDNN 직접 설치 | O (Apt 패키지 매니저 사용) | X (Docker Hub에서 NVIDIA가 제공하는 사전 설치 이미지를 사용하므로 직접 작업할 필요 없음) |
| 이식성 | 다른 시스템으로 이전할 때마다 개발환경을 새로 구축해야 함 | Docker 기반이므로, 제작해 둔 Dockerfile로 필요할 때마다 새로운 이미지를 빌드하거나 기존에 사용하던 이미지(추가 볼륨이나 네트워크 설정 제외)를 쉽게 이식 가능 |
| cuDNN 외 추가적인 GPU 가속 라이브러리 활용 | X | CuPy, cuDF, cuML, DALI 도입 |
| Jupyter Notebook 인터페이스 | Jupyter Notebook (classic) | JupyterLab (Next-Generation) |
| SSH 서버 설정 | 따로 다루지 않음 | 3편에서 기초적인 SSH 서버 설정 구성을 포함 |
Docker가 아닌 venv 등의 파이썬 가상환경을 활용하고 싶다면, 기존에 작성한 이 글 역시 여전히 유효하므로 계속해서 읽어도 괜찮다. 높은 이식성 등 Docker 컨테이너 도입의 장점을 누리고 싶거나, Fedora 등 Ubuntu 이외의 다른 리눅스 배포판을 사용할 예정이거나, NVIDIA 그래픽카드를 사용하는 환경이고 CuPy, cuDF, cuML, DALI 등 추가적인 GPU 가속 라이브러리를 활용하고 싶거나, 또는 SSH 및 JupyterLab 설정을 통해 원격 접속하고 싶다면 새로운 가이드도 참고해 보는 것을 추천한다.
0. 사전 확인사항
- 머신러닝 공부를 위해서는 리눅스 사용을 권장한다. 윈도우 상에서도 가능은 하지만, 여러 자잘한 부분에서 시간낭비가 많이 일어날 수 있다. 우분투 최신 LTS 버전을 사용하는 것이 제일 무난하다. 오픈소스가 아닌 독점 드라이버들도 자동 설치되어 편리하며, 사용자 수가 많기 때문에 대부분의 기술 문서가 우분투 기준으로 작성되어 있다.
- 일반적으로 우분투를 비롯한 대부분의 리눅스 배포판에는 파이썬이 기본 설치되어 있다. 그러나 만약 파이썬이 설치되어 있지 않다면, 이 글을 따라하기에 앞서 파이썬을 먼저 설치해야 한다.
- 현재 설치된 파이썬 버전은 다음 명령어로 확인 가능하다.
1
$ python3 --version
- 텐서플로2 혹은 파이토치를 사용할 것이라면 호환 가능한 파이썬 버전을 확인해야 한다. 이 글 작성 시점을 기준으로 파이토치 최신 버전이 지원하는 파이썬 버전은 3.6-3.8, 텐서플로2 최신 버전이 지원하는 파이썬 버전은 3.5-3.8이다.
이 글에서는 파이썬 3.8 버전을 사용한다.
- 현재 설치된 파이썬 버전은 다음 명령어로 확인 가능하다.
- 로컬 머신에서 머신러닝을 공부할 계획이라면 GPU를 하나 이상 준비하는 것이 좋다. 데이터 전처리 정도는 CPU로도 가능하지만, 모델 학습 단계에서는 모델의 규모가 커질수록 CPU와 GPU의 학습 속도 차이는 압도적이다(특히 딥러닝의 경우가 그렇다).
- 머신러닝을 위해서라면 GPU 제조사 선택지는 사실상 하나뿐이다. NVIDIA 제품을 이용해야 한다. NVIDIA는 머신러닝 분야에 상당히 많은 투자를 해 온 회사이며, 거의 모든 머신러닝 프레임워크에서 NVIDIA의 CUDA 라이브러리를 이용한다.
- 머신러닝용으로 GPU를 사용할 계획이라면, 사용하려는 그래픽카드가 CUDA 사용이 가능한 모델인지 우선 확인해야 한다. 현재 컴퓨터에 장착된 GPU 모델명은 터미널에서
uname -m && cat /etc/*release명령으로 확인 가능하다. 링크에 있는 GPU 목록에서 해당하는 모델명을 찾은 뒤, Compute Capability 수치를 확인하자. 이 수치가 적어도 3.5 이상이어야 CUDA 사용이 가능하다. - GPU 선정 기준은 다음 글에 잘 정리되어 있다. 글쓴이가 지속적으로 업데이트하고 있는 글이다.
Which GPU(s) to Get for Deep Learning
같은 분이 작성한 A Full Hardware Guide to Deep Learning이라는 글도 매우 유익하다. 참고로 위 글의 결론은 아래와 같다.The RTX 3070 and RTX 3080 are mighty cards, but they lack a bit of memory. For many tasks, however, you do not need that amount of memory.
The RTX 3070 is perfect if you want to learn deep learning. This is so because the basic skills of training most architectures can be learned by just scaling them down a bit or using a bit smaller input images. If I would learn deep learning again, I would probably roll with one RTX 3070, or even multiple if I have the money to spare. The RTX 3080 is currently by far the most cost-efficient card and thus ideal for prototyping. For prototyping, you want the largest memory, which is still cheap. With prototyping, I mean here prototyping in any area: Research, competitive Kaggle, hacking ideas/models for a startup, experimenting with research code. For all these applications, the RTX 3080 is the best GPU.
위에서 언급한 모든 사항들을 충족하였다면 작업환경 구축을 시작하자.
1. 작업 디렉터리 생성
터미널을 열고 .bashrc 파일을 수정하여 환경변수를 등록한다($ 프롬프트 다음이 명령이다).
우선 다음 명령을 이용해 nano 에디터를 연다(vim이나 그 외에 다른 에디터도 상관없다).
1
$ nano ~/.bashrc
마지막 줄에 다음 내용을 추가한다. 큰따옴표 안의 내용은 원한다면 다른 경로로 바꿔도 된다.
export ML_PATH="$HOME/ml"
Ctrl+O를 눌러 저장한 뒤 Ctrl+X로 빠져나온다.
이제 아래 명령어를 실행하여 환경변수를 적용한다.
1
$ source ~/.bashrc
디렉터리를 생성한다.
1
$ mkdir -p $ML_PATH
2. pip 패키지 관리자 설치
머신러닝을 위해 필요한 파이썬 패키지들을 설치하는 방법은 여러 가지이다. 아나콘다 같은 과학 파이썬 배포판을 이용해도 되고(윈도우 운영체제의 경우 권장하는 방법), 파이썬 자체 패키징 도구인 pip를 사용할 수도 있다. 여기서는 리눅스나 맥OS의 배시 셸(bash shell)에서 pip 명령을 사용할 것이다.
시스템에 pip가 설치되어 있는지 다음 명령으로 확인한다.
1
2
3
4
5
6
$ pip3 --version
명령어 'pip3' 을(를) 찾을 수 없습니다. 그러나 다음을 통해 설치할 수 있습니다:
sudo apt install python3-pip
위와 같이 나온다면 시스템에 pip가 설치되지 않은 것이다. 시스템의 패키지 매니저(여기선 apt)를 사용하여 설치해준다(만약 버전명이 나온다면, 설치되어 있는 것이니 이 명령은 건너뛴다).
1
$ sudo apt install python3-pip
이제 시스템에 pip가 설치되었다.
3. 독립적인 가상환경 만들기(권장)
가상환경(다른 프로젝트의 라이브러리 버전과 충돌하는 것을 피하기 위함)을 만들기 위해서는 venv를 설치한다.
1
$ sudo apt install python3-venv
그런 다음 독립적인 파이썬 환경을 다음과 같이 생성한다. 이렇게 하는 이유는 프로젝트마다 필요한 라이브러리 버전이 달라 충돌하는 것을 막기 위함이므로, 새 프로젝트를 시작할 때마다 새로운 가상환경을 생성해서 독립된 환경을 구축해주면 된다.
1
2
$ cd $ML_PATH
$ python3 -m venv --system-site-packages ./(환경 이름)
이 가상환경을 활성화하려면 터미널을 열고 다음 명령을 입력하면 된다.
1
2
$ cd $ML_PATH
$ source ./(환경 이름)/bin/activate
가상환경을 활성화한 후 가상환경 안의 pip를 업그레이드한다.
1
(env) $ pip install -U pip
나중에 가상환경을 비활성화하려면 deactivate 명령을 사용한다. 환경을 활성화한 상태에서는 pip 명령으로 설치하는 어떤 패키지든 독립된 이 환경에 설치되고 파이썬은 이 패키지를 사용한다.
3′. (가상환경을 만들지 않는 경우) pip 버전 업그레이드하기
시스템에 pip를 설치할 시 배포판(여기선 우분투)의 미러 서버에 있는 바이너리 파일을 다운로드받아 설치하게 되는데, 이 바이너리 파일은 일반적으로 업데이트가 늦어 최신버전이 아닌 경우가 많다(필자의 경우 20.3.4 버전이 설치되었다). 최신 버전의 pip를 사용하기 위해 다음 명령을 실행하여 사용자의 홈 디렉터리에 pip를 설치(혹은 이미 설치되어 있다면 업그레이드)한다.
1
2
3
4
5
$ python3 -m pip install -U pip
Collecting pip
(중략)
Successfully installed pip-21.0.1
pip가 이 글을 작성한 시점 기준으로 최신인 21.0.1 버전으로 설치된 것을 볼 수 있다. 이때 사용자 홈 디렉터리에 설치한 pip는 시스템에서 자동으로 인식하지 못하므로, 시스템에서 인식하고 사용할 수 있게끔 PATH 환경변수로 등록해야 한다.
다시 .bashrc 파일을 에디터로 연다.
1
$ nano ~/.bashrc
이번에는 export PATH=으로 시작하는 줄을 찾는다. 만약 그 뒤에 적힌 경로가 없다면 그냥 1단계에서 한 것처럼 내용을 추가해주면 된다. 기존에 등록된 다른 경로가 있다면 콜론을 사용하여 그 뒤에 내용을 추가해준다.
export PATH="$HOME/.local/bin"
export PATH="(기존 경로):$HOME/.local/bin"
시스템 pip를 시스템 패키지 매니저 이외의 다른 방법으로 업그레이드하면 버전 충돌로 인해 문제가 발생할 수 있다. 그래서 사용자의 홈 디렉터리에 별도로 pip를 설치하는 것이다. 같은 이유로 가상환경 내에서가 아니라면 pip 명령 대신 python3 -m pip 명령을 이용하여 pip를 사용하는 것이 좋다.
4. 머신러닝용 패키지(jupyter, matplotlib, numpy, pandas, scipy, scikit-learn) 설치
다음 pip 명령으로 필요한 패키지와 의존성으로 연결된 다른 패키지를 모두 설치한다.
필자의 경우 venv를 사용하기 때문에 그냥 pip 명령을 사용하였는데, 만약 venv를 사용하지 않는다면 앞서 언급하였듯이 python3 -m pip 명령을 대신 사용하는 것을 권장한다.
1
2
3
4
5
6
(env) $ pip install -U jupyter matplotlib numpy pandas scipy scikit-learn
Collecting jupyter
Downloading jupyter-1.0.0-py2.py3-none-any.whl (2.7 kB)
Collecting matplotlib
(후략)
venv를 사용했다면 주피터에 커널을 등록하고 이름을 정한다.
1
(env) $ python3 -m ipykernel install --user --name=(커널 이름)
이제부터 주피터를 실행하려면 다음 명령을 이용하면 된다.
1
(env) $ jupyter notebook
5. CUDA & cuDNN 설치
5-1. 필요한 CUDA & cuDNN 버전 확인
파이토치 공식 문서에서 지원하는 CUDA 버전을 확인한다.

파이토치 1.7.1 버전 기준으로 지원하는 CUDA 버전은 9.2, 10.1, 10.2, 11.0이다. NVIDIA 30시리즈 GPU의 경우 CUDA 11을 필요로 하므로, 11.0 버전이 필요하다는 것을 알 수 있다.
텐서플로2 공식 문서에서도 필요한 CUDA 버전을 확인한다.
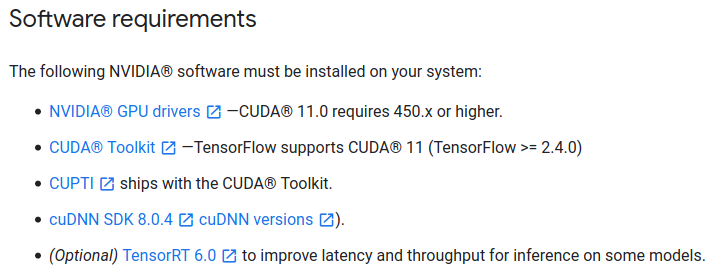
텐서플로 2.4.0 버전 기준으로, CUDA는 마찬가지로 11.0 버전, cuDNN은 8.0 버전이 필요한 것을 확인하였다.
필자는 경우에 따라 파이토치를 사용할 때도, 텐서플로2를 사용할 때도 있기 때문에 두 패키지 모두 호환 가능한 CUDA 버전을 확인하였다. 자신이 필요한 패키지의 요구 조건을 확인하여 거기에 맞추면 된다.
5-2. CUDA 설치
CUDA Toolkit Archive에 접속한 다음 앞에서 확인한 버전을 선택하여 들어간다. 이 글에서는 CUDA Toolkit 11.0 Update1을 선택해 들어간다.
이제 해당하는 플랫폼과 인스톨러 종류를 선택하고, 화면에 나타나는 지시를 따르면 된다. 이때 인스톨러의 경우 가급적 시스템 패키지 매니저를 이용하는 것이 좋다. 필자가 선호하는 방법은 deb (network)이다.
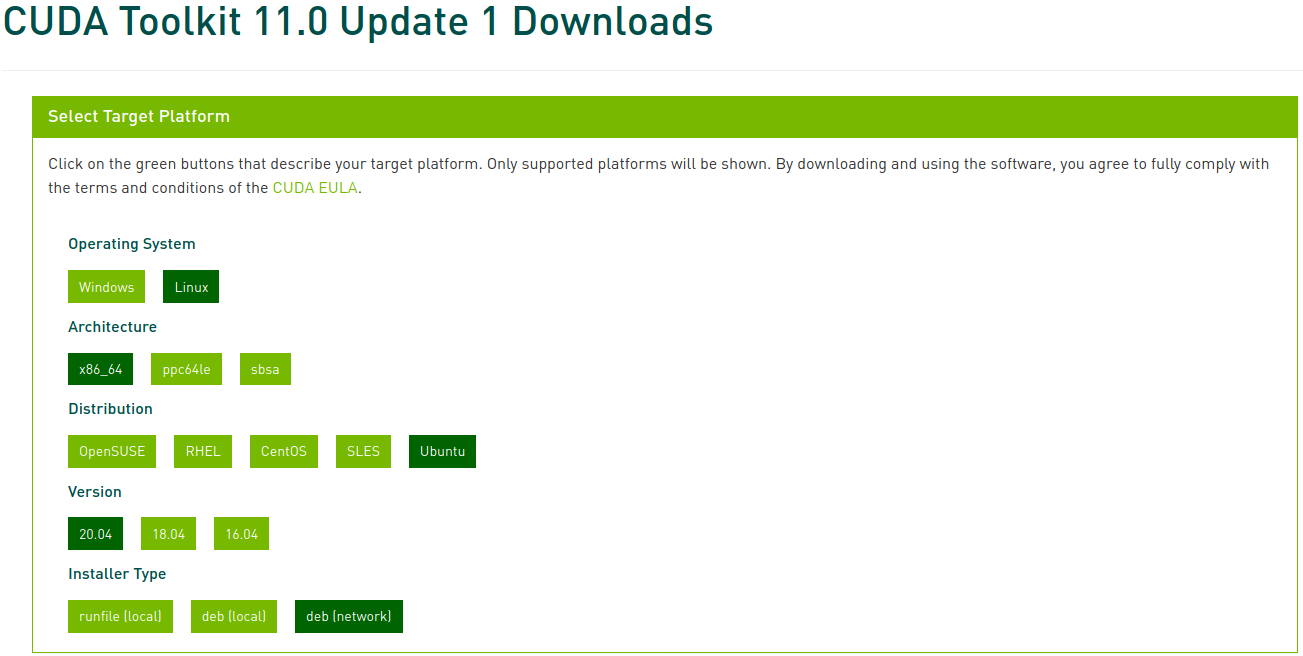
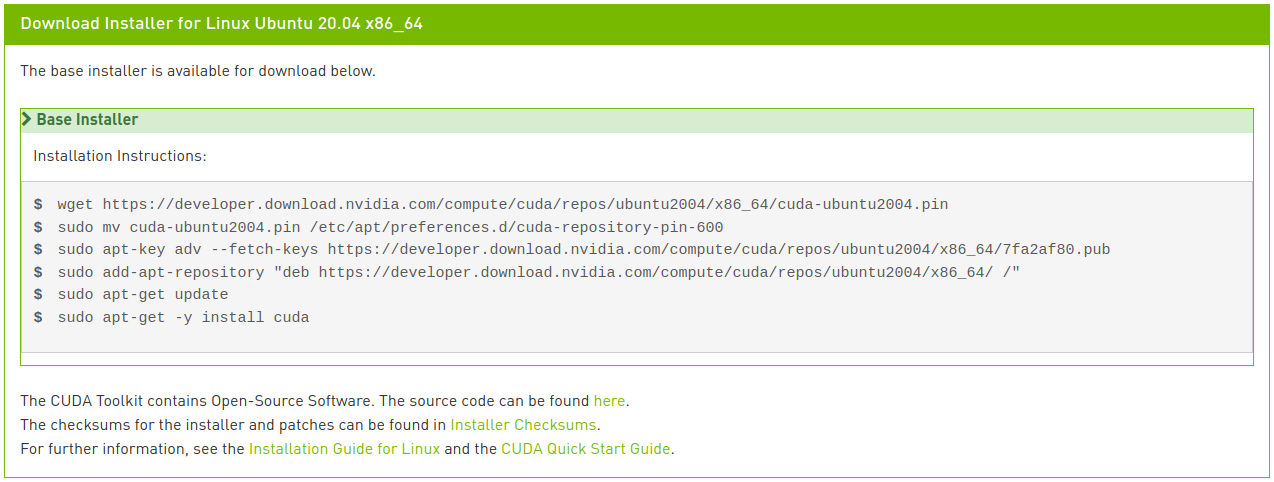
아래 명령을 실행하여 CUDA를 설치한다.
1
2
3
4
5
6
$ wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/cuda-ubuntu2004.pin
$ sudo mv cuda-ubuntu2004.pin /etc/apt/preferences.d/cuda-repository-pin-600
$ sudo apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/7fa2af80.pub
$ sudo add-apt-repository "deb https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/ /"
$ sudo apt update
$ sudo apt install cuda-toolkit-11-0 cuda-drivers
눈썰미가 좋다면 마지막 줄이 이미지에 나타난 지시와 약간 다르다는 것을 알아챘을 것이다. 네트워크 설치에서 이미지에 나타난 대로 cuda만 입력하면 최신 버전인 11.2 버전이 설치되는데, 이는 우리가 원하는 바가 아니다. CUDA 11.0 리눅스 설치 가이드에서 여러 메타 패키지 옵션을 살펴볼 수 있다. 여기서는 CUDA Toolkit 패키지를 11.0 버전으로 지정 설치하고, 드라이버 패키지는 자동 업그레이드 되도록 하기 위해 마지막 줄을 수정하였다.
5-3. cuDNN 설치
다음과 같이 cuDNN을 설치한다.
1
2
$ sudo apt install libcudnn8=8.0.5.39-1+cuda11.0
$ sudo apt install libcudnn8-dev=8.0.5.39-1+cuda11.0
6. PyTorch 설치
앞서 3단계에서 가상환경을 생성하였다면 사용할 가상환경을 활성화한 상태로 진행한다. 파이토치가 필요하지 않다면 이 단계는 건너뛴다.
PyTorch 홈페이지에 접속하여 설치할 파이토치 빌드(Stable)와 운영체제(Linux), 패키지(Pip), 언어(Python), CUDA(11.0)을 선택하고 화면에 나타나는 지시를 따른다.
1
(env) $ pip install torch==1.7.1+cu110 torchvision==0.8.2+cu110 torchaudio===0.7.2 -f https://download.pytorch.org/whl/torch_stable.html
파이토치를 제대로 설치했는지 검증하기 위해 파이썬 인터프리터 실행 후 다음 명령을 실행해본다. 텐서가 반환된다면 성공한 것이다.
1
2
3
4
5
6
7
8
9
10
11
12
(env) $ python3
Python 3.8.5 (default, Jul 28 2020, 12:59:40)
[GCC 9.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
>>> x = torch.rand(5, 3)
>>> print(x)"
tensor([[0.8187, 0.5925, 0.2768],
[0.9884, 0.8298, 0.8553],
[0.6350, 0.7243, 0.2323],
[0.9205, 0.9239, 0.9065],
[0.2424, 0.1018, 0.3426]])
GPU 드라이버와 CUDA가 활성화되어 있고 사용 가능한지 확인하기 위해 다음 명령을 실행해본다.
1
2
>>> torch.cuda.is_available()
True
7. TensorFlow 2 설치
텐서플로가 필요하지 않다면 이 단계는 무시하면 된다.
6단계에서 파이토치를 가상환경에 설치하였다면, 그 가상환경은 비활성화한 후 3, 4단계로 돌아가 새로운 가상환경을 생성하고 활성화한 뒤 진행한다. 6단계를 건너뛰었다면 그냥 그대로 진행하면 된다.
다음과 같이 텐서플로를 설치한다.
1
(env2) $ pip install --upgrade tensorflow
텐서플로를 제대로 설치했는지 검증하기 위해 다음 명령을 실행해본다. GPU 이름을 표시하고, 텐서를 반환한다면 성공한 것이다.
1
2
3
4
5
6
(env2) $ python -c "import tensorflow as tf;print(tf.reduce_sum(tf.random.normal([1000, 1000])))"
2021-02-07 22:45:51.390640: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0
(중략)
2021-02-07 22:45:54.592749: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1406] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 6878 MB memory) -> physical GPU (device: 0, name: GeForce RTX 3070, pci bus id: 0000:01:00.0, compute capability: 8.6)
tf.Tensor(526.1059, shape=(), dtype=float32)