機械学習開発環境の構築方法
この記事では、ローカルマシンで機械学習を学ぶための第一歩となる開発環境の構築方法について説明します。すべての内容はUbuntu 20.04 LTS上でNVIDIA Geforce RTX 3070グラフィックカードを基準に作成しました。

概要
この記事では、ローカルマシンで機械学習を学ぶための第一歩となる開発環境の構築方法について説明します。すべての内容はUbuntu 20.04 LTS上でNVIDIA Geforce RTX 3070グラフィックカードを基準に作成しました。
- 構築する技術スタック
- Ubuntu 20.04 LTS
- Python 3.8
- pip 21.0.1
- jupyter
- matplotlib
- numpy
- pandas
- scipy
- scikit-learn
- CUDA 11.0.3
- cuDNN 8.0.5
- ディープラーニングフレームワーク(各環境につき一つだけ選択してインストールすることを推奨)
- PyTorch 1.7.1
- TensorFlow 2.4.0
新しく作成した機械学習開発環境構築ガイドとの比較表
ブログに投稿してから3年半ほど経過していますが、このガイドの内容はパッケージのバージョンやNVIDIAオープンソースドライバーの発表などの細部を除けば、大枠では依然として有効です。しかし、人類紀元 12024年の夏に新しいPCを購入して開発環境を構築する際にいくつかの変更点があったため、新しい開発環境構築ガイドを作成しました。変更点は以下の表の通りです。
| 相違点 | 本文(12021バージョン) | 新しい記事(12024バージョン) |
|---|---|---|
| Linuxディストリビューション | Ubuntuベース | Ubuntu以外にもFedora/RHEL/Centos、 Debian、openSUSE/SLESなどにも適用可能 |
| 開発環境構築方式 | venvを利用したPython仮想環境 | NVIDIA Container Toolkitを利用した Dockerコンテナベースの環境 |
| NVIDIAグラフィックドライバーのインストール | O | O |
| ホストシステムに CUDAおよびcuDNNを直接インストール | O(Aptパッケージマネージャーを使用) | X(Docker HubでNVIDIAが提供する事前インストール イメージを使用するため直接作業不要) |
| 移植性 | 別のシステムに移行するたびに 開発環境を新たに構築する必要がある | Dockerベースのため、作成しておいたDockerfileで 必要に応じて新しいイメージをビルドしたり、 既存のイメージ(追加ボリュームやネットワーク 設定を除く)を簡単に移植可能 |
| cuDNN以外の追加 GPU高速化ライブラリの活用 | X | CuPy、cuDF、cuML、DALIの導入 |
| Jupyter Notebookインターフェース | Jupyter Notebook(classic) | JupyterLab(Next-Generation) |
| SSHサーバー設定 | 特に扱わない | 3編で基本的なSSHサーバー設定構成を含む |
Dockerではなくvenvなどのpython仮想環境を活用したい場合は、既存のこの記事も依然として有効なので、引き続き読んでも問題ありません。高い移植性などDockerコンテナ導入のメリットを享受したい場合や、FedoraなどUbuntu以外の他のLinuxディストリビューションを使用する予定がある場合、またはNVIDIAグラフィックカードを使用する環境でCuPy、cuDF、cuML、DALIなどの追加GPU高速化ライブラリを活用したい場合、あるいはSSHおよびJupyterLab設定を通じてリモートアクセスしたい場合は、新しいガイドも参考にすることをお勧めします。
0. 事前確認事項
- 機械学習の学習にはLinuxの使用を推奨します。Windowsでも可能ですが、様々な細かい部分で時間の無駄が発生する可能性があります。Ubuntu最新LTSバージョンを使用するのが最も無難です。オープンソースではない独占ドライバーも自動インストールされて便利であり、ユーザー数が多いため、ほとんどの技術文書がUbuntuを基準に作成されています。
- 一般的にUbuntuをはじめとするほとんどのLinuxディストリビューションにはPythonがデフォルトでインストールされています。しかし、もしPythonがインストールされていない場合は、この記事に従う前にPythonをインストールする必要があります。
- 現在インストールされているPythonのバージョンは次のコマンドで確認できます。
1
$ python3 --version
- TensorFlow2またはPyTorchを使用する場合は、互換性のあるPythonバージョンを確認する必要があります。この記事の執筆時点でPyTorch最新バージョンがサポートするPythonバージョンは3.6-3.8、TensorFlow2最新バージョンがサポートするPythonバージョンは3.5-3.8です。
この記事ではPython 3.8バージョンを使用します。
- 現在インストールされているPythonのバージョンは次のコマンドで確認できます。
- ローカルマシンで機械学習を学ぶ計画がある場合は、GPUを少なくとも1つ準備することをお勧めします。データの前処理程度ならCPUでも可能ですが、モデル学習段階ではモデルの規模が大きくなるほどCPUとGPUの学習速度の差は圧倒的です(特にディープラーニングの場合)。
- 機械学習のためであれば、GPU製造メーカーの選択肢は実質的に一つしかありません。NVIDIA製品を利用する必要があります。NVIDIAは機械学習分野にかなり多くの投資をしてきた会社であり、ほぼすべての機械学習フレームワークでNVIDIAのCUDAライブラリを利用しています。
- 機械学習用にGPUを使用する予定がある場合は、使用しようとするグラフィックカードがCUDA使用可能なモデルかどうかを確認する必要があります。現在のコンピュータに装着されているGPUモデル名はターミナルで
uname -m && cat /etc/*releaseコマンドで確認できます。リンクにあるGPUリストから該当するモデル名を見つけた後、Compute Capabilityの数値を確認しましょう。この数値が少なくとも3.5以上であればCUDAが使用可能です。 - GPU選定基準は次の記事によくまとめられています。筆者が継続的に更新している記事です。
Which GPU(s) to Get for Deep Learning
同じ方が書いたA Full Hardware Guide to Deep Learningという記事も非常に有益です。参考までに上記記事の結論は以下の通りです。The RTX 3070 and RTX 3080 are mighty cards, but they lack a bit of memory. For many tasks, however, you do not need that amount of memory.
The RTX 3070 is perfect if you want to learn deep learning. This is so because the basic skills of training most architectures can be learned by just scaling them down a bit or using a bit smaller input images. If I would learn deep learning again, I would probably roll with one RTX 3070, or even multiple if I have the money to spare. The RTX 3080 is currently by far the most cost-efficient card and thus ideal for prototyping. For prototyping, you want the largest memory, which is still cheap. With prototyping, I mean here prototyping in any area: Research, competitive Kaggle, hacking ideas/models for a startup, experimenting with research code. For all these applications, the RTX 3080 is the best GPU.
上記のすべての事項を満たしていれば、作業環境の構築を始めましょう。
1. 作業ディレクトリの作成
ターミナルを開き、.bashrcファイルを修正して環境変数を登録します($プロンプトの後がコマンドです)。
まず次のコマンドを使用してnanoエディタを開きます(vimやその他のエディタでも構いません)。
1
$ nano ~/.bashrc
最後の行に次の内容を追加します。二重引用符内の内容は希望すれば別のパスに変更しても構いません。
export ML_PATH="$HOME/ml"
Ctrl+Oを押して保存した後、Ctrl+Xで終了します。
次に以下のコマンドを実行して環境変数を適用します。
1
$ source ~/.bashrc
ディレクトリを作成します。
1
$ mkdir -p $ML_PATH
2. pipパッケージマネージャーのインストール
機械学習に必要なPythonパッケージをインストールする方法はいくつかあります。Anacondaのような科学Python配布版を利用しても良いですし(Windows OSの場合は推奨される方法)、Python自体のパッケージングツールであるpipを使用することもできます。ここではLinuxやmacOSのbashシェルでpipコマンドを使用します。
システムにpipがインストールされているかどうかを次のコマンドで確認します。
1
2
3
4
5
6
$ pip3 --version
コマンド 'pip3' が見つかりません。ただし、以下の方法でインストールできます:
sudo apt install python3-pip
上記のように表示される場合、システムにpipがインストールされていません。システムのパッケージマネージャー(ここではapt)を使用してインストールします(もしバージョン名が表示される場合は、すでにインストールされているので、このコマンドはスキップします)。
1
$ sudo apt install python3-pip
これでシステムにpipがインストールされました。
3. 独立した仮想環境の作成(推奨)
仮想環境(他のプロジェクトのライブラリバージョンとの衝突を避けるため)を作成するには、venvをインストールします。
1
$ sudo apt install python3-venv
次に、独立したPython環境を以下のように作成します。これを行う理由は、プロジェクトごとに必要なライブラリのバージョンが異なり、衝突を防ぐためです。新しいプロジェクトを開始するたびに新しい仮想環境を作成して独立した環境を構築すれば良いです。
1
2
$ cd $ML_PATH
$ python3 -m venv --system-site-packages ./(環境名)
この仮想環境を有効化するには、ターミナルを開いて次のコマンドを入力します。
1
2
$ cd $ML_PATH
$ source ./(環境名)/bin/activate
仮想環境を有効化した後、仮想環境内のpipをアップグレードします。
1
(env) $ pip install -U pip
後で仮想環境を無効化するにはdeactivateコマンドを使用します。環境を有効化した状態では、pipコマンドでインストールするどのパッケージも独立したこの環境にインストールされ、Pythonはこのパッケージを使用します。
3′. (仮想環境を作成しない場合)pipバージョンのアップグレード
システムにpipをインストールする際、ディストリビューション(ここではUbuntu)のミラーサーバーにあるバイナリファイルをダウンロードしてインストールしますが、このバイナリファイルは一般的に更新が遅く、最新バージョンではない場合が多いです(筆者の場合、20.3.4バージョンがインストールされました)。最新バージョンのpipを使用するために次のコマンドを実行してユーザーのホームディレクトリにpipをインストール(または既にインストールされている場合はアップグレード)します。
1
2
3
4
5
$ python3 -m pip install -U pip
Collecting pip
(中略)
Successfully installed pip-21.0.1
pipがこの記事を書いた時点での最新バージョンである21.0.1にインストールされたことが確認できます。この時、ユーザーのホームディレクトリにインストールしたpipはシステムが自動的に認識できないため、システムが認識して使用できるようにPATH環境変数に登録する必要があります。
再び.bashrcファイルをエディタで開きます。
1
$ nano ~/.bashrc
今度はexport PATH=で始まる行を探します。もしその後に書かれたパスがなければ、ステップ1で行ったように内容を追加するだけです。既に登録された他のパスがある場合は、コロンを使用してその後に内容を追加します。
export PATH="$HOME/.local/bin"
export PATH="(既存のパス):$HOME/.local/bin"
システムpipをシステムパッケージマネージャー以外の方法でアップグレードすると、バージョンの衝突により問題が発生する可能性があります。そのため、ユーザーのホームディレクトリに別途pipをインストールします。同じ理由で、仮想環境内でない限り、pipコマンドの代わりにpython3 -m pipコマンドを使用してpipを使用することをお勧めします。
4. 機械学習用パッケージ(jupyter、matplotlib、numpy、pandas、scipy、scikit-learn)のインストール
次のpipコマンドで必要なパッケージと依存関係で接続された他のパッケージをすべてインストールします。
筆者の場合はvenvを使用しているため、単にpipコマンドを使用しましたが、venvを使用しない場合は前述のようにpython3 -m pipコマンドを代わりに使用することをお勧めします。
1
2
3
4
5
6
(env) $ pip install -U jupyter matplotlib numpy pandas scipy scikit-learn
Collecting jupyter
Downloading jupyter-1.0.0-py2.py3-none-any.whl (2.7 kB)
Collecting matplotlib
(後略)
venvを使用した場合は、Jupyterにカーネルを登録して名前を付けます。
1
(env) $ python3 -m ipykernel install --user --name=(カーネル名)
これからJupyterを実行するには次のコマンドを使用します。
1
(env) $ jupyter notebook
5. CUDA & cuDNNのインストール
5-1. 必要なCUDA & cuDNNバージョンの確認
PyTorch公式ドキュメントでサポートされているCUDAバージョンを確認します。

PyTorch 1.7.1バージョンでサポートされているCUDAバージョンは9.2、10.1、10.2、11.0です。NVIDIA 30シリーズGPUの場合はCUDA 11が必要なため、11.0バージョンが必要であることがわかります。
TensorFlow2公式ドキュメントでも必要なCUDAバージョンを確認します。
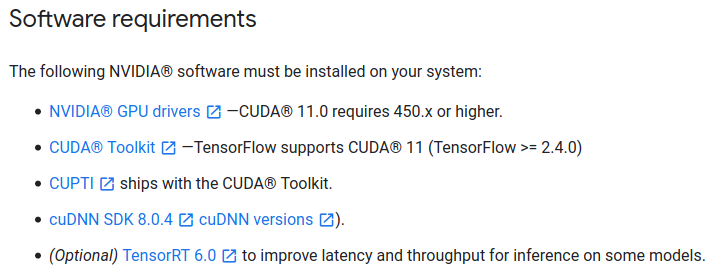
TensorFlow 2.4.0バージョンでは、CUDAも同様に11.0バージョン、cuDNNは8.0バージョンが必要であることを確認しました。
筆者の場合、状況に応じてPyTorchを使用することもあれば、TensorFlow2を使用することもあるため、両方のパッケージと互換性のあるCUDAバージョンを確認しました。自分が必要とするパッケージの要件を確認して、それに合わせれば良いです。
5-2. CUDAのインストール
CUDA Toolkit Archiveにアクセスし、前で確認したバージョンを選択して進みます。この記事ではCUDA Toolkit 11.0 Update1を選択します。
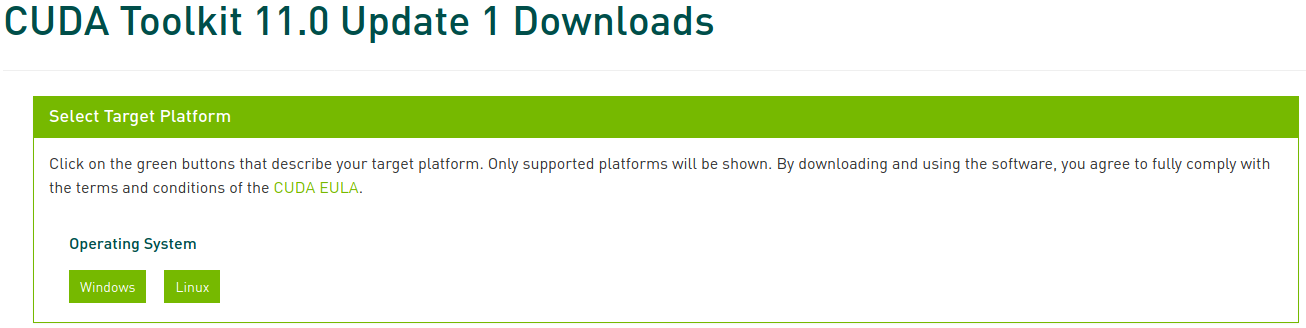
次に該当するプラットフォームとインストーラーの種類を選択し、画面に表示される指示に従います。この時、インストーラーの場合、できるだけシステムパッケージマネージャーを利用することをお勧めします。筆者が好む方法はdeb(network)です。
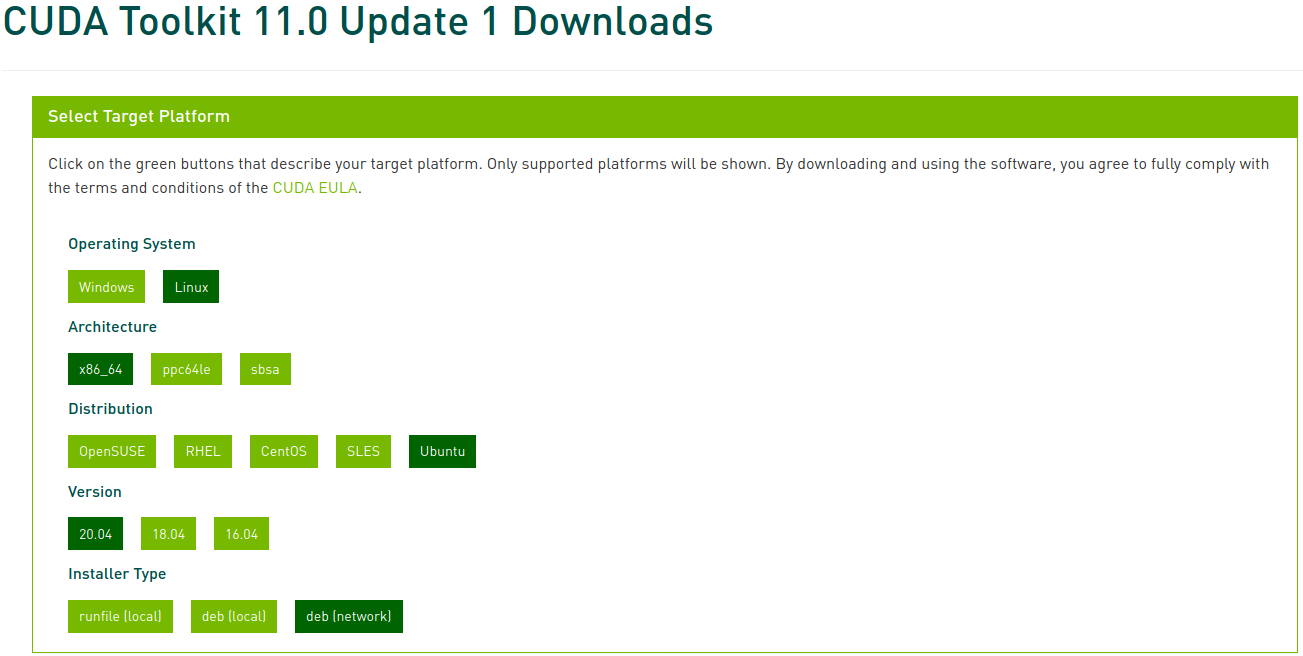
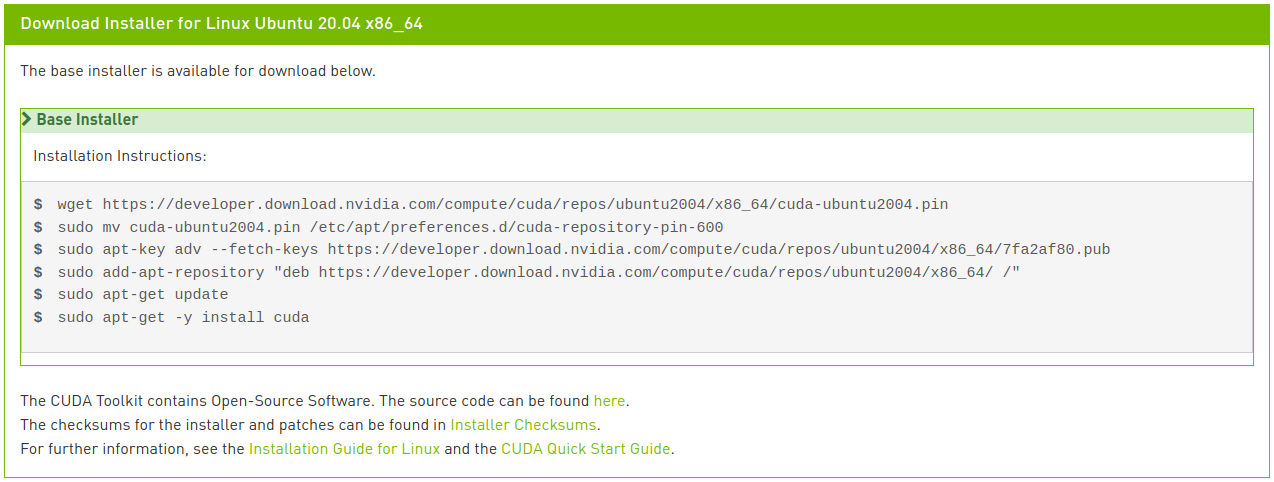
以下のコマンドを実行してCUDAをインストールします。
1
2
3
4
5
6
$ wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/cuda-ubuntu2004.pin
$ sudo mv cuda-ubuntu2004.pin /etc/apt/preferences.d/cuda-repository-pin-600
$ sudo apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/7fa2af80.pub
$ sudo add-apt-repository "deb https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/ /"
$ sudo apt update
$ sudo apt install cuda-toolkit-11-0 cuda-drivers
目のいい人なら、最後の行が画像に表示されている指示と少し異なることに気づいたかもしれません。ネットワークインストールで画像に表示されている通りcudaだけを入力すると、最新バージョンである11.2バージョンがインストールされますが、これは私たちが望むものではありません。CUDA 11.0 Linuxインストールガイドで様々なメタパッケージオプションを確認できます。ここではCUDA Toolkitパッケージを11.0バージョンに指定してインストールし、ドライバーパッケージは自動アップグレードされるようにするために最後の行を修正しました。
5-3. cuDNNのインストール
次のようにcuDNNをインストールします。
1
2
$ sudo apt install libcudnn8=8.0.5.39-1+cuda11.0
$ sudo apt install libcudnn8-dev=8.0.5.39-1+cuda11.0
6. PyTorchのインストール
前のステップ3で仮想環境を作成した場合は、使用する仮想環境を有効化した状態で進めます。PyTorchが必要ない場合は、このステップはスキップします。
PyTorchホームページにアクセスして、インストールするPyTorchビルド(Stable)、オペレーティングシステム(Linux)、パッケージ(Pip)、言語(Python)、CUDA(11.0)を選択し、画面に表示される指示に従います。
1
(env) $ pip install torch==1.7.1+cu110 torchvision==0.8.2+cu110 torchaudio===0.7.2 -f https://download.pytorch.org/whl/torch_stable.html
PyTorchが正しくインストールされたかを検証するために、Pythonインタープリターを実行して次のコマンドを試します。テンソルが返されれば成功です。
1
2
3
4
5
6
7
8
9
10
11
12
(env) $ python3
Python 3.8.5 (default, Jul 28 2020, 12:59:40)
[GCC 9.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
>>> x = torch.rand(5, 3)
>>> print(x)"
tensor([[0.8187, 0.5925, 0.2768],
[0.9884, 0.8298, 0.8553],
[0.6350, 0.7243, 0.2323],
[0.9205, 0.9239, 0.9065],
[0.2424, 0.1018, 0.3426]])
GPUドライバーとCUDAが有効化されていて使用可能かどうかを確認するために次のコマンドを試します。
1
2
>>> torch.cuda.is_available()
True
7. TensorFlow 2のインストール
TensorFlowが必要ない場合は、このステップは無視して構いません。
ステップ6でPyTorchを仮想環境にインストールした場合は、その仮想環境を無効化した後、ステップ3、4に戻って新しい仮想環境を作成して有効化してから進めます。ステップ6をスキップした場合は、そのまま進めます。
次のようにTensorFlowをインストールします。
1
(env2) $ pip install --upgrade tensorflow
TensorFlowが正しくインストールされたかを検証するために次のコマンドを実行します。GPU名が表示され、テンソルが返されれば成功です。
1
2
3
4
5
6
(env2) $ python -c "import tensorflow as tf;print(tf.reduce_sum(tf.random.normal([1000, 1000])))"
2021-02-07 22:45:51.390640: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0
(中略)
2021-02-07 22:45:54.592749: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1406] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 6878 MB memory) -> physical GPU (device: 0, name: GeForce RTX 3070, pci bus id: 0000:01:00.0, compute capability: 8.6)
tf.Tensor(526.1059, shape=(), dtype=float32)