Comment traduire automatiquement des articles avec l'API Claude 3.5 Sonnet (2) - Écriture et application d'un script d'automatisation
Cet article traite de la conception d'un prompt pour la traduction multilingue de fichiers texte Markdown, et du processus d'automatisation en Python en utilisant une clé API obtenue auprès d'Anthropic et le prompt créé. C'est le deuxième article de cette série, qui présente l'obtention et l'intégration de l'API ainsi que la méthode d'écriture du script Python.
Introduction
J’ai récemment adopté l’API Claude 3.5 Sonnet d’Anthropic pour la traduction multilingue des articles de mon blog. Dans cette série, je vais expliquer pourquoi j’ai choisi l’API Claude 3.5 Sonnet, comment j’ai conçu le prompt, et comment j’ai implémenté l’automatisation via un script Python connecté à l’API.
La série se compose de deux articles, et celui que vous lisez est le deuxième article de cette série.
- Partie 1 : Introduction au modèle Claude 3.5 Sonnet, raisons de sa sélection, et ingénierie de prompt
- Partie 2 : Écriture et application d’un script d’automatisation Python utilisant l’API (cet article)
Avant de commencer
Cet article fait suite à la partie 1, donc si vous ne l’avez pas encore lue, il est recommandé de commencer par là.
Intégration de l’API Claude
Obtention d’une clé API Claude
Cette section explique comment obtenir une nouvelle clé API Claude. Si vous avez déjà une clé API à utiliser, vous pouvez passer cette étape.
Connectez-vous à https://console.anthropic.com. Si vous n’avez pas encore de compte, vous devrez d’abord vous inscrire. Une fois connecté, vous verrez un écran de tableau de bord comme celui-ci.
En cliquant sur le bouton ‘Get API keys’ sur cet écran, vous verrez l’écran suivant.
 J’ai déjà une clé créée, donc une clé nommée
J’ai déjà une clé créée, donc une clé nommée yunseo-secret-key est affichée, mais si vous venez de créer votre compte et n’avez pas encore obtenu de clé API, vous n’aurez probablement aucune clé listée. Cliquez sur le bouton ‘Create Key’ en haut à droite pour obtenir une nouvelle clé.
Une fois la clé générée, votre clé API sera affichée à l’écran. Comme cette clé ne pourra plus être consultée ultérieurement, assurez-vous de la noter soigneusement dans un endroit sûr.
(Recommandé) Enregistrement de la clé API Claude dans une variable d’environnement
Pour utiliser l’API Claude dans un script Python ou Shell, vous devez charger la clé API. Bien qu’il soit possible d’enregistrer la clé API directement dans le script, cette méthode n’est pas utilisable si vous devez partager le script avec d’autres personnes, par exemple en le téléchargeant sur GitHub. De plus, même si vous n’aviez pas l’intention de partager le fichier de script, il y a un risque que la clé API soit également divulguée en cas de fuite accidentelle du fichier de script si la clé API y est enregistrée. Il est donc recommandé d’enregistrer la clé API dans une variable d’environnement de votre système personnel et de la charger dans le script à partir de cette variable d’environnement. Voici comment enregistrer la clé API dans une variable d’environnement système, basé sur un système UNIX. Pour Windows, veuillez vous référer à d’autres articles en ligne.
- Dans le terminal, exécutez
nano ~/.bashrcounano ~/.zshrcselon le shell que vous utilisez pour lancer l’éditeur. - Ajoutez
export ANTHROPIC_API_KEY='your-api-key-here'au contenu du fichier. Remplacez ‘your-api-key-here’ par votre propre clé API, en veillant à l’entourer de guillemets simples. - Sauvegardez les modifications et quittez l’éditeur.
- Exécutez
source ~/.bashrcousource ~/.zshrcdans le terminal pour appliquer les changements.
Installation des packages Python nécessaires
Si le package anthropic n’est pas installé dans votre environnement Python, installez-le avec la commande suivante :
1
pip3 install anthropic
De plus, les packages suivants sont nécessaires pour utiliser le script de traduction d’articles que nous allons présenter plus loin, alors installez-les ou mettez-les à jour avec la commande suivante :
1
pip3 install -U argparse tqdm
Écriture du script Python
Le script de traduction d’articles que nous allons présenter dans cet article se compose de trois fichiers de script Python et d’un fichier CSV.
compare_hash.py: Calcule les valeurs de hachage SHA256 des articles originaux en coréen dans le répertoire_posts/ko, les compare aux valeurs de hachage existantes enregistrées dans le fichierhash.csv, et renvoie une liste des noms de fichiers modifiés ou nouvellement ajoutés.hash.csv: Fichier CSV enregistrant les valeurs de hachage SHA256 des fichiers d’articles existants.prompt.py: Reçoit les valeurs filepath, source_lang, target_lang, charge la valeur de la clé API Claude à partir de la variable d’environnement système, puis appelle l’API en soumettant le prompt écrit précédemment comme prompt système et le contenu de l’article à traduire situé dans ‘filepath’ comme prompt utilisateur. Ensuite, il reçoit la réponse (le résultat de la traduction) du modèle Claude 3.5 Sonnet et l’écrit dans un fichier texte au chemin'../_posts/' + language_code[target_lang] + '/' + filename.translate_changes.py: Contient une variable de chaîne source_lang et une liste ‘target_langs’, appelle la fonctionchanged_files()danscompare_hash.pypour obtenir la liste de variables changed_files. S’il y a des fichiers modifiés, il exécute une double boucle pour tous les fichiers de la liste changed_files et tous les éléments de la liste target_langs, et dans cette boucle, il appelle la fonctiontranslate(filepath, source_lang, target_lang)dansprompt.pypour effectuer la traduction.
Le contenu des fichiers de script complétés peut également être consulté sur le dépôt GitHub yunseo-kim/yunseo-kim.github.io.
compare_hash.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
import os
import hashlib
import csv
default_source_lang_code = "ko"
def compute_file_hash(file_path):
sha256_hash = hashlib.sha256()
with open(file_path, "rb") as f:
for byte_block in iter(lambda: f.read(4096), b""):
sha256_hash.update(byte_block)
return sha256_hash.hexdigest()
def load_existing_hashes(csv_path):
existing_hashes = {}
if os.path.exists(csv_path):
with open(csv_path, 'r') as csvfile:
reader = csv.reader(csvfile)
for row in reader:
if len(row) == 2:
existing_hashes[row[0]] = row[1]
return existing_hashes
def update_hash_csv(csv_path, file_hashes):
# Trie les hachages de fichiers par nom de fichier (les clés du dictionnaire)
sorted_file_hashes = dict(sorted(file_hashes.items()))
with open(csv_path, 'w', newline='') as csvfile:
writer = csv.writer(csvfile)
for file_path, hash_value in sorted_file_hashes.items():
writer.writerow([file_path, hash_value])
def changed_files(source_lang_code):
posts_dir = '../_posts/' + source_lang_code + '/'
hash_csv_path = './hash.csv'
existing_hashes = load_existing_hashes(hash_csv_path)
current_hashes = {}
changed_files = []
for root, _, files in os.walk(posts_dir):
for file in files:
if not file.endswith('.md'): # Traite uniquement les fichiers .md
continue
file_path = os.path.join(root, file)
relative_path = os.path.relpath(file_path, start=posts_dir)
current_hash = compute_file_hash(file_path)
current_hashes[relative_path] = current_hash
if relative_path in existing_hashes:
if current_hash != existing_hashes[relative_path]:
changed_files.append(relative_path)
else:
changed_files.append(relative_path)
update_hash_csv(hash_csv_path, current_hashes)
return changed_files
if __name__ == "__main__":
initial_wd = os.getcwd()
os.chdir(os.path.abspath(os.path.dirname(__file__)))
changed_files = changed_files(default_source_lang_code)
if changed_files:
print("Fichiers modifiés :")
for file in changed_files:
print(f"- {file}")
else:
print("Aucun fichier n'a été modifié.")
os.chdir(initial_wd)
prompt.py
Comme le contenu du fichier inclut le prompt écrit précédemment et est donc assez long, je le remplace par un lien vers le fichier source dans le dépôt GitHub.
https://github.com/yunseo-kim/yunseo-kim.github.io/blob/main/tools/prompt.py
Dans le fichier
prompt.pydu lien ci-dessus,max_tokensest une variable qui spécifie la longueur maximale de sortie, indépendamment de la taille de la fenêtre de contexte. Bien que la taille de la fenêtre de contexte que vous pouvez entrer en une fois lors de l’utilisation de l’API Claude soit de 200k tokens (environ 680 000 caractères), indépendamment de cela, chaque modèle a un nombre maximum de tokens de sortie défini, il est donc recommandé de vérifier à l’avance dans la documentation officielle d’Anthropic avant d’utiliser l’API. Les modèles de la série Claude 3 existants pouvaient produire jusqu’à 4096 tokens maximum, et bien que cela n’ait pas posé de problème pour la plupart des articles de ce blog lors des tests, pour certains articles assez longs d’environ 8000 caractères ou plus en coréen, il y avait un problème où la partie arrière de la traduction était coupée dans certaines langues de sortie car elle dépassait 4096 tokens. Dans le cas de Claude 3.5 Sonnet, le nombre maximum de tokens de sortie a doublé à 8192, donc il n’y a généralement pas eu de problème de dépassement de cette limite de tokens de sortie maximum, et dans le fichierprompt.pydu dépôt GitHub ci-dessus,max_tokens=8192a été spécifié.
translate_changes.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
import sys
import os
from tqdm import tqdm
import compare_hash
import prompt
def is_valid_file(filename):
# Motifs de fichiers à exclure
excluded_patterns = [
'.DS_Store', # Fichier système macOS
'~', # Fichier temporaire
'.tmp', # Fichier temporaire
'.temp', # Fichier temporaire
'.bak', # Fichier de sauvegarde
'.swp', # Fichier temporaire vim
'.swo' # Fichier temporaire vim
]
# Renvoie False si le nom de fichier contient l'un des motifs d'exclusion
return not any(pattern in filename for pattern in excluded_patterns)
posts_dir = '../_posts/'
source_lang = "Korean"
target_langs = ["English", "Japanese", "Taiwanese Mandarin","Spanish", "Brazilian Portuguese", "French", "German"]
source_lang_code = "ko"
target_lang_codes = ["en", "ja", "zh-TW", "es", "pt-BR", "fr", "de"]
if __name__ == "__main__":
initial_wd = os.getcwd()
os.chdir(os.path.abspath(os.path.dirname(__file__)))
changed_files = compare_hash.changed_files(source_lang_code)
# Filtrage des fichiers temporaires
changed_files = [f for f in changed_files if is_valid_file(f)]
if not changed_files:
sys.exit("Aucun fichier n'a été modifié.")
print("Fichiers modifiés :")
for file in changed_files:
print(f"- {file}")
print("")
print("*** Début de la traduction ! ***")
# Boucle externe : progression des fichiers modifiés
for changed_file in tqdm(changed_files, desc="Fichiers", position=0):
filepath = os.path.join(posts_dir, source_lang_code, changed_file)
# Boucle interne : progression de la traduction par langue pour chaque fichier
for target_lang in tqdm(target_langs, desc="Langues", position=1, leave=False):
prompt.translate(filepath, source_lang, target_lang)
print("\nTraduction terminée !")
os.chdir(initial_wd)
Comment utiliser le script Python
Pour un blog Jekyll, placez des sous-répertoires par code de langue ISO 639-1 dans le répertoire /_posts où se trouvent les articles, comme /_posts/ko, /_posts/en, /_posts/pt-BR. Ensuite, placez les scripts Python et le fichier CSV présentés ci-dessus dans le répertoire /tools, puis ouvrez un terminal à cet emplacement et exécutez la commande suivante.
1
python3 translate_changes.py
Le script s’exécutera alors et un écran comme celui-ci s’affichera.
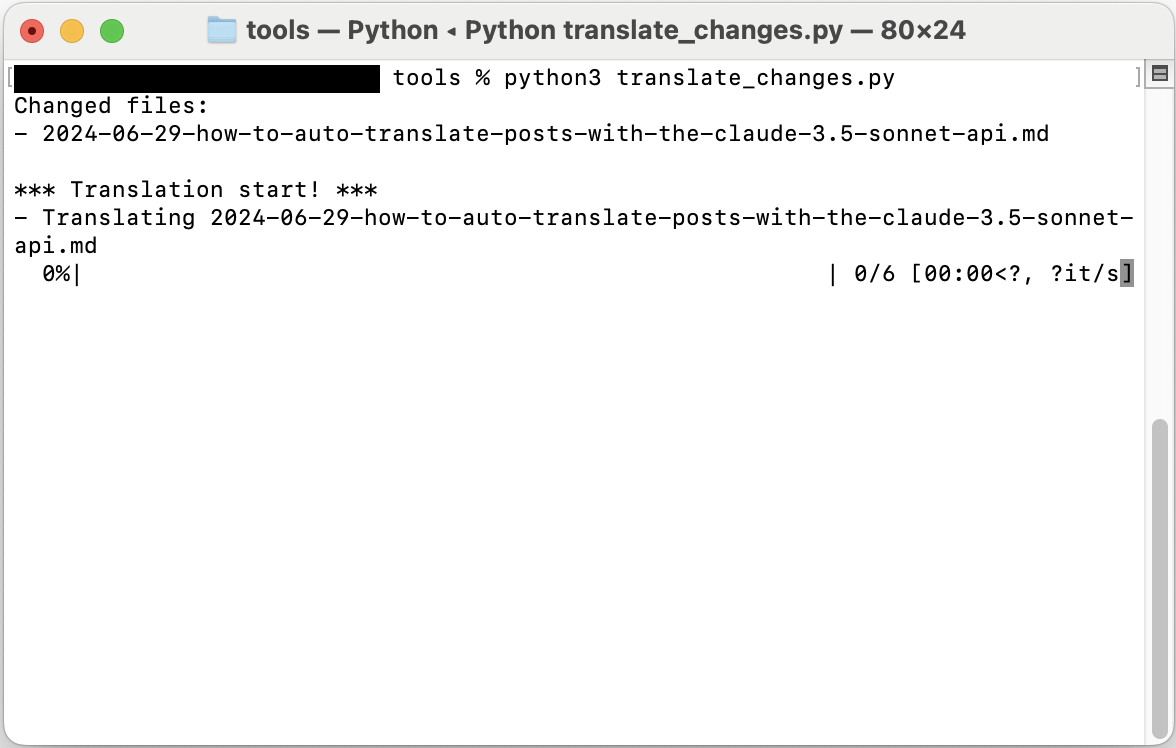
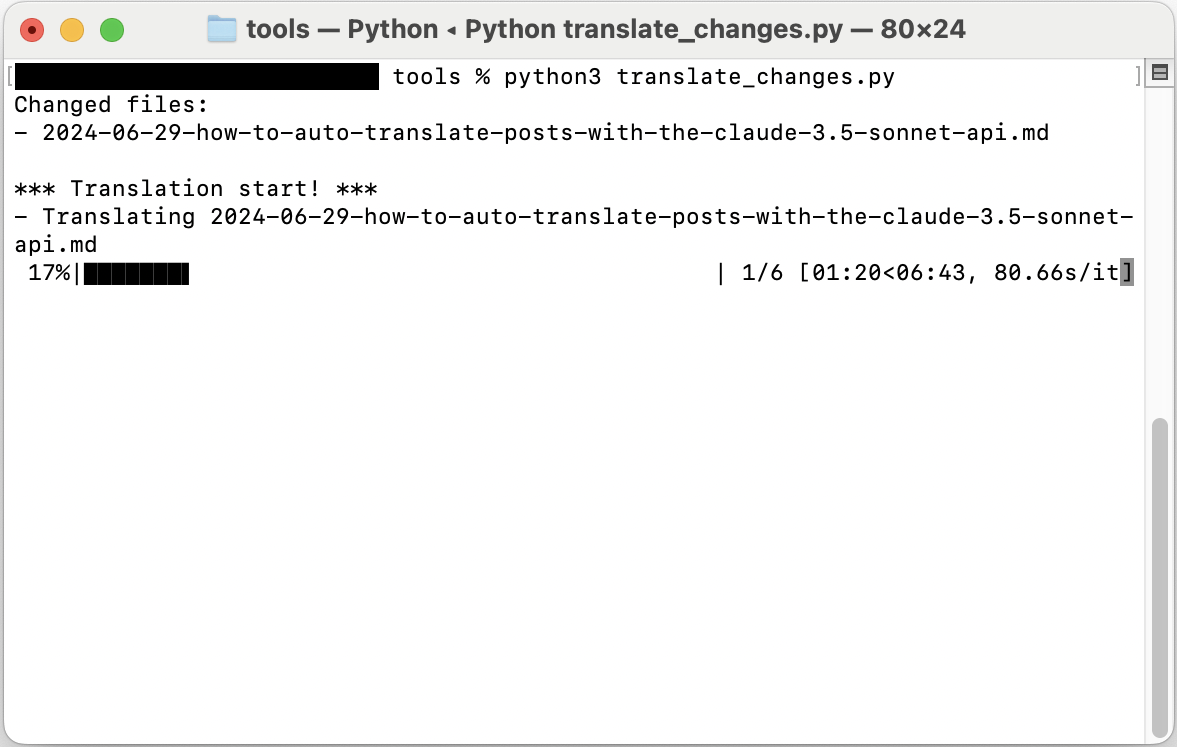
Retour d’expérience
Comme mentionné précédemment, j’utilise la traduction automatique des articles via l’API Claude 3.5 sur ce blog depuis environ 2 mois. Dans la plupart des cas, on peut obtenir des traductions de haute qualité sans nécessiter d’intervention humaine supplémentaire, et après avoir traduit et publié les articles en plusieurs langues, j’ai effectivement constaté un trafic Organic Search provenant de recherches dans des régions autres que la Corée, comme le Brésil, le Canada, les États-Unis et la France. De plus, en plus d’augmenter le trafic du blog, il y avait un avantage supplémentaire en termes d’apprentissage pour l’auteur de l’article. Comme Claude produit des textes assez fluides en anglais, lors du processus de révision avant de pousser l’article vers le dépôt GitHub Pages, j’ai l’opportunité de voir comment certains termes ou expressions de mon texte original en coréen peuvent être exprimés naturellement en anglais. Bien que cela seul ne soit pas suffisant pour un apprentissage complet de l’anglais, le fait de pouvoir fréquemment rencontrer des expressions anglaises naturelles, non seulement pour des expressions quotidiennes mais aussi pour des expressions et termes académiques, en utilisant comme exemple un texte que j’ai écrit moi-même et qui m’est plus familier que tout autre, sans effort supplémentaire particulier, semble être un avantage assez important pour un étudiant de premier cycle en ingénierie dans un pays non anglophone comme la Corée.