Construire un environnement de développement pour le Machine Learning
Cet article traite de la méthode de configuration d'un environnement de développement, qui peut être considérée comme la première étape pour étudier le machine learning sur une machine locale. Tout le contenu a été rédigé sur la base d'Ubuntu 20.04 LTS avec une carte graphique NVIDIA Geforce RTX 3070.

Aperçu
Cet article traite de la méthode de configuration d’un environnement de développement, qui peut être considérée comme la première étape pour étudier le machine learning sur une machine locale. Tout le contenu a été rédigé sur la base d’Ubuntu 20.04 LTS avec une carte graphique NVIDIA Geforce RTX 3070.
- Stack technologique à mettre en place
- Ubuntu 20.04 LTS
- Python 3.8
- pip 21.0.1
- jupyter
- matplotlib
- numpy
- pandas
- scipy
- scikit-learn
- CUDA 11.0.3
- cuDNN 8.0.5
- Frameworks de deep learning (il est recommandé de n’en installer qu’un seul par environnement)
- PyTorch 1.7.1
- TensorFlow 2.4.0
Tableau comparatif avec le nouveau guide de configuration d’environnement de machine learning
Bien que cet article ait été publié il y a environ 3 ans et demi, son contenu reste largement valable, à l’exception de quelques détails comme les versions des packages et l’annonce des pilotes open source NVIDIA. Cependant, en achetant un nouveau PC et en configurant un environnement de développement pendant l’été 12024 du calendrier holocène, j’ai constaté quelques changements et j’ai donc rédigé un nouveau guide de configuration d’environnement. Les différences sont résumées dans le tableau ci-dessous.
| Différence | Cet article (version 12021) | Nouvel article (version 12024) |
|---|---|---|
| Distribution Linux | Basé sur Ubuntu | Applicable à d’autres distributions comme Fedora/RHEL/Centos, Debian, openSUSE/SLES en plus d’Ubuntu |
| Méthode de configuration | Environnement virtuel Python avec venv | Environnement basé sur conteneurs Docker utilisant NVIDIA Container Toolkit |
| Installation du pilote graphique NVIDIA | O | O |
| Installation directe de CUDA et cuDNN sur le système hôte | O (utilisation du gestionnaire de paquets Apt) | X (utilisation d’images préinstallées fournies par NVIDIA sur Docker Hub, donc pas besoin de le faire manuellement) |
| Portabilité | Nécessité de reconfigurer l’environnement à chaque migration vers un autre système | Basé sur Docker, donc possibilité de construire facilement de nouvelles images avec le Dockerfile créé ou de porter des images existantes (hors configurations de volumes ou réseau supplémentaires) |
| Utilisation de bibliothèques d’accélération GPU supplémentaires en plus de cuDNN | X | Introduction de CuPy, cuDF, cuML, DALI |
| Interface Jupyter Notebook | Jupyter Notebook (classique) | JupyterLab (nouvelle génération) |
| Configuration du serveur SSH | Non abordée | Inclut une configuration de base du serveur SSH dans la partie 3 |
Si vous préférez utiliser un environnement virtuel Python comme venv plutôt que Docker, cet article reste valable. Si vous souhaitez profiter des avantages des conteneurs Docker comme la haute portabilité, si vous prévoyez d’utiliser une distribution Linux autre qu’Ubuntu comme Fedora, si vous utilisez une carte graphique NVIDIA et souhaitez utiliser des bibliothèques d’accélération GPU supplémentaires comme CuPy, cuDF, cuML, DALI, ou si vous souhaitez configurer un accès à distance via SSH et JupyterLab, je vous recommande également de consulter le nouveau guide.
0. Prérequis
- L’utilisation de Linux est recommandée pour l’étude du machine learning. Bien que ce soit possible sous Windows, cela peut entraîner de nombreuses pertes de temps sur divers aspects. La version LTS la plus récente d’Ubuntu est généralement le choix le plus sûr. Elle permet l’installation automatique de pilotes propriétaires non open source, et comme elle compte de nombreux utilisateurs, la plupart de la documentation technique est rédigée pour Ubuntu.
- Python est généralement préinstallé sur la plupart des distributions Linux, y compris Ubuntu. Cependant, si Python n’est pas installé, vous devrez l’installer avant de suivre ce guide.
- Vous pouvez vérifier la version de Python installée avec la commande suivante :
1
$ python3 --version
- Si vous prévoyez d’utiliser TensorFlow 2 ou PyTorch, vous devez vérifier les versions Python compatibles. Au moment de la rédaction de cet article, les versions Python prises en charge par la dernière version de PyTorch sont 3.6-3.8, et les versions Python prises en charge par la dernière version de TensorFlow 2 sont 3.5-3.8.
Dans cet article, nous utilisons Python 3.8.
- Vous pouvez vérifier la version de Python installée avec la commande suivante :
- Si vous prévoyez d’étudier le machine learning sur une machine locale, il est préférable de disposer d’au moins un GPU. Bien que le prétraitement des données soit possible avec un CPU, la différence de vitesse d’apprentissage entre CPU et GPU devient considérable à mesure que la taille du modèle augmente (surtout dans le cas du deep learning).
- Pour le machine learning, le choix du fabricant de GPU est pratiquement limité à un seul : NVIDIA. NVIDIA a beaucoup investi dans le domaine du machine learning, et presque tous les frameworks de machine learning utilisent la bibliothèque CUDA de NVIDIA.
- Si vous prévoyez d’utiliser un GPU pour le machine learning, vous devez d’abord vérifier si votre carte graphique est compatible avec CUDA. Vous pouvez vérifier le modèle de GPU installé dans votre ordinateur en exécutant la commande
uname -m && cat /etc/*releasedans le terminal. Trouvez le modèle correspondant dans la liste des GPU sur ce lien et vérifiez la valeur Compute Capability. Cette valeur doit être d’au moins 3.5 pour pouvoir utiliser CUDA. - Les critères de sélection des GPU sont bien résumés dans l’article suivant, que l’auteur met régulièrement à jour :
Which GPU(s) to Get for Deep Learning
L’article A Full Hardware Guide to Deep Learning du même auteur est également très instructif. Pour référence, voici la conclusion de l’article ci-dessus :The RTX 3070 and RTX 3080 are mighty cards, but they lack a bit of memory. For many tasks, however, you do not need that amount of memory.
The RTX 3070 is perfect if you want to learn deep learning. This is so because the basic skills of training most architectures can be learned by just scaling them down a bit or using a bit smaller input images. If I would learn deep learning again, I would probably roll with one RTX 3070, or even multiple if I have the money to spare. The RTX 3080 is currently by far the most cost-efficient card and thus ideal for prototyping. For prototyping, you want the largest memory, which is still cheap. With prototyping, I mean here prototyping in any area: Research, competitive Kaggle, hacking ideas/models for a startup, experimenting with research code. For all these applications, the RTX 3080 is the best GPU.
Si vous remplissez toutes les conditions mentionnées ci-dessus, commençons à configurer l’environnement de travail.
1. Création du répertoire de travail
Ouvrez un terminal et modifiez le fichier .bashrc pour enregistrer une variable d’environnement (la commande suit le prompt $).
Tout d’abord, ouvrez l’éditeur nano avec la commande suivante (vim ou tout autre éditeur convient également) :
1
$ nano ~/.bashrc
Ajoutez la ligne suivante à la fin du fichier. Vous pouvez changer le chemin entre guillemets si vous le souhaitez :
export ML_PATH="$HOME/ml"
Appuyez sur Ctrl+O pour sauvegarder, puis sur Ctrl+X pour quitter.
Maintenant, exécutez la commande suivante pour appliquer la variable d’environnement :
1
$ source ~/.bashrc
Créez le répertoire :
1
$ mkdir -p $ML_PATH
2. Installation du gestionnaire de paquets pip
Il existe plusieurs façons d’installer les paquets Python nécessaires au machine learning. Vous pouvez utiliser une distribution Python scientifique comme Anaconda (méthode recommandée pour Windows), ou utiliser pip, l’outil de packaging natif de Python. Ici, nous utiliserons la commande pip dans le shell bash de Linux ou macOS.
Vérifiez si pip est installé sur votre système avec la commande suivante :
1
2
3
4
5
6
$ pip3 --version
Commande 'pip3' introuvable. Vous pouvez l'installer en exécutant :
sudo apt install python3-pip
Si vous voyez ce message, pip n’est pas installé sur votre système. Installez-le avec le gestionnaire de paquets de votre système (apt dans ce cas) (si une version apparaît, pip est déjà installé et vous pouvez sauter cette commande) :
1
$ sudo apt install python3-pip
Pip est maintenant installé sur votre système.
3. Création d’un environnement virtuel indépendant (recommandé)
Pour créer un environnement virtuel (afin d’éviter les conflits de versions de bibliothèques avec d’autres projets), installez venv :
1
$ sudo apt install python3-venv
Ensuite, créez un environnement Python indépendant comme suit. Cela permet d’éviter les conflits entre les versions de bibliothèques nécessaires à différents projets, donc vous devriez créer un nouvel environnement virtuel chaque fois que vous commencez un nouveau projet :
1
2
$ cd $ML_PATH
$ python3 -m venv --system-site-packages ./(nom de l'environnement)
Pour activer cet environnement virtuel, ouvrez un terminal et entrez la commande suivante :
1
2
$ cd $ML_PATH
$ source ./(nom de l'environnement)/bin/activate
Après avoir activé l’environnement virtuel, mettez à jour pip dans cet environnement :
1
(env) $ pip install -U pip
Pour désactiver l’environnement virtuel plus tard, utilisez la commande deactivate. Lorsque l’environnement est activé, tout paquet installé avec pip sera installé dans cet environnement isolé, et Python utilisera ces paquets.
3′. (Si vous ne créez pas d’environnement virtuel) Mise à jour de pip
Lorsque vous installez pip sur votre système, vous téléchargez et installez un fichier binaire depuis le serveur miroir de la distribution (Ubuntu dans ce cas), qui n’est généralement pas à jour (dans mon cas, la version 20.3.4 a été installée). Pour utiliser la dernière version de pip, exécutez la commande suivante pour installer (ou mettre à jour si déjà installé) pip dans le répertoire personnel de l’utilisateur :
1
2
3
4
5
$ python3 -m pip install -U pip
Collecting pip
(abrégé)
Successfully installed pip-21.0.1
On peut voir que pip a été installé en version 21.0.1, la plus récente au moment de la rédaction de cet article. Comme le pip installé dans le répertoire personnel de l’utilisateur n’est pas automatiquement reconnu par le système, nous devons l’enregistrer comme variable d’environnement PATH pour que le système puisse le reconnaître et l’utiliser.
Ouvrez à nouveau le fichier .bashrc avec un éditeur :
1
$ nano ~/.bashrc
Cette fois, cherchez la ligne commençant par export PATH=. S’il n’y a pas de chemin après, ajoutez simplement le contenu comme à l’étape 1. S’il y a déjà d’autres chemins enregistrés, ajoutez le contenu après en utilisant deux points :
export PATH="$HOME/.local/bin"
export PATH="(chemin existant):$HOME/.local/bin"
La mise à jour de pip système par une méthode autre que le gestionnaire de paquets système peut causer des problèmes de conflit de versions. C’est pourquoi nous installons pip séparément dans le répertoire personnel de l’utilisateur. Pour la même raison, il est préférable d’utiliser la commande python3 -m pip au lieu de pip pour utiliser pip en dehors d’un environnement virtuel.
4. Installation des paquets pour le machine learning (jupyter, matplotlib, numpy, pandas, scipy, scikit-learn)
Installez tous les paquets nécessaires et leurs dépendances avec la commande pip suivante.
Comme j’utilise venv, j’utilise simplement la commande pip, mais si vous n’utilisez pas venv, il est recommandé d’utiliser la commande python3 -m pip comme mentionné précédemment.
1
2
3
4
5
6
(env) $ pip install -U jupyter matplotlib numpy pandas scipy scikit-learn
Collecting jupyter
Downloading jupyter-1.0.0-py2.py3-none-any.whl (2.7 kB)
Collecting matplotlib
(suite omise)
Si vous utilisez venv, enregistrez un noyau pour Jupyter et donnez-lui un nom :
1
(env) $ python3 -m ipykernel install --user --name=(nom du noyau)
Pour exécuter Jupyter à partir de maintenant, utilisez la commande suivante :
1
(env) $ jupyter notebook
5. Installation de CUDA & cuDNN
5-1. Vérification des versions CUDA & cuDNN nécessaires
Vérifiez les versions CUDA prises en charge dans la documentation officielle de PyTorch.

Pour PyTorch 1.7.1, les versions CUDA prises en charge sont 9.2, 10.1, 10.2 et 11.0. Les GPU NVIDIA série 30 nécessitent CUDA 11, donc nous avons besoin de la version 11.0.
Vérifiez également les versions CUDA nécessaires dans la documentation officielle de TensorFlow 2.
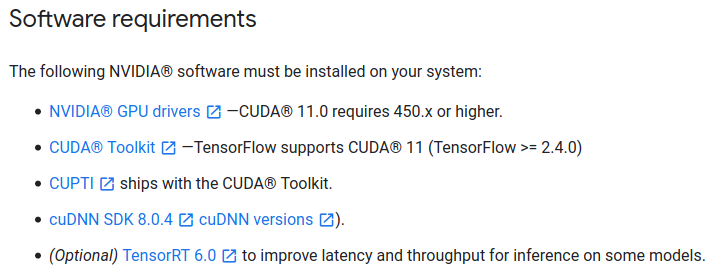
Pour TensorFlow 2.4.0, nous avons également besoin de CUDA 11.0 et cuDNN 8.0.
J’ai vérifié les versions CUDA compatibles avec les deux packages car j’utilise parfois PyTorch et parfois TensorFlow 2. Vous devez vérifier les exigences du package dont vous avez besoin et vous y conformer.
5-2. Installation de CUDA
Accédez aux archives CUDA Toolkit et sélectionnez la version que vous avez identifiée précédemment. Dans cet article, nous sélectionnons CUDA Toolkit 11.0 Update1.
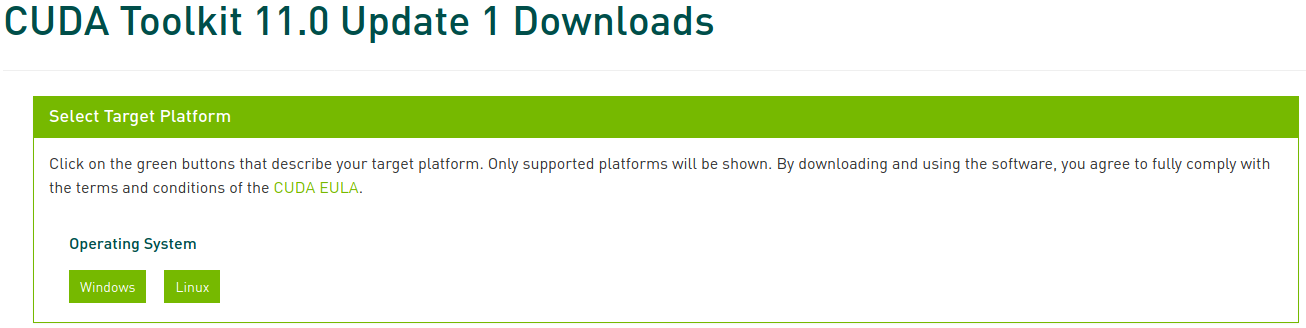
Sélectionnez maintenant la plateforme et le type d’installateur correspondants, puis suivez les instructions à l’écran. Il est préférable d’utiliser le gestionnaire de paquets système pour l’installateur. Je préfère personnellement l’option deb (network).
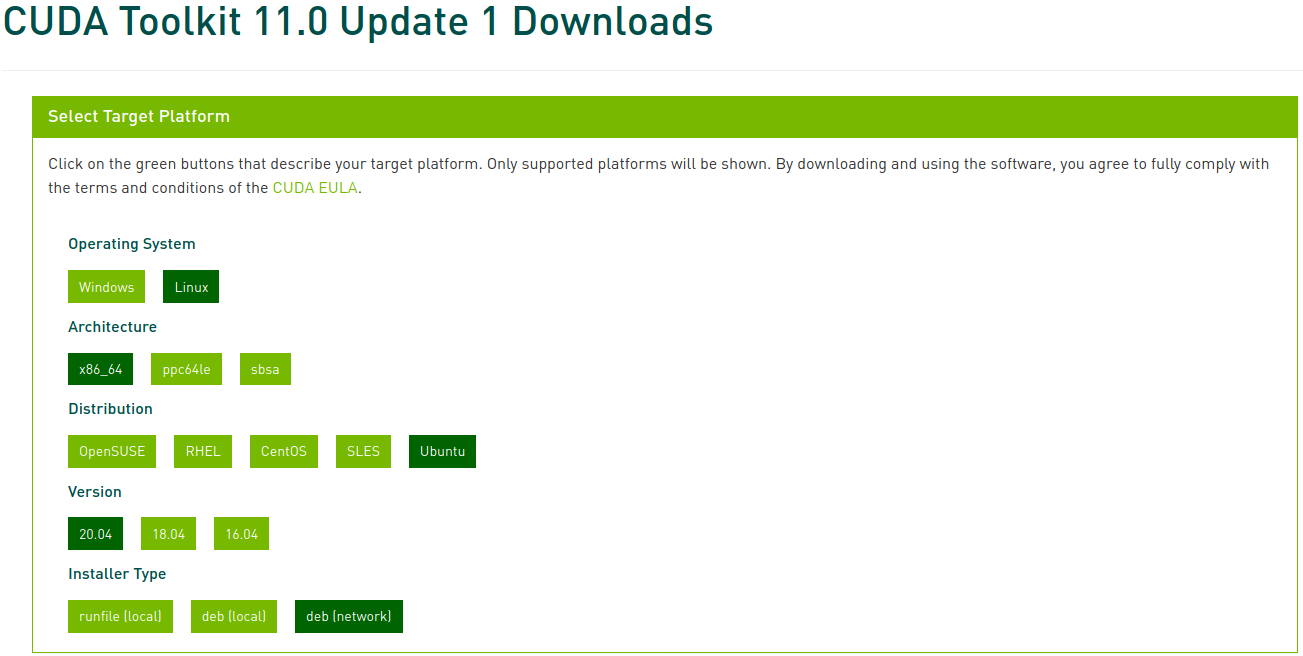
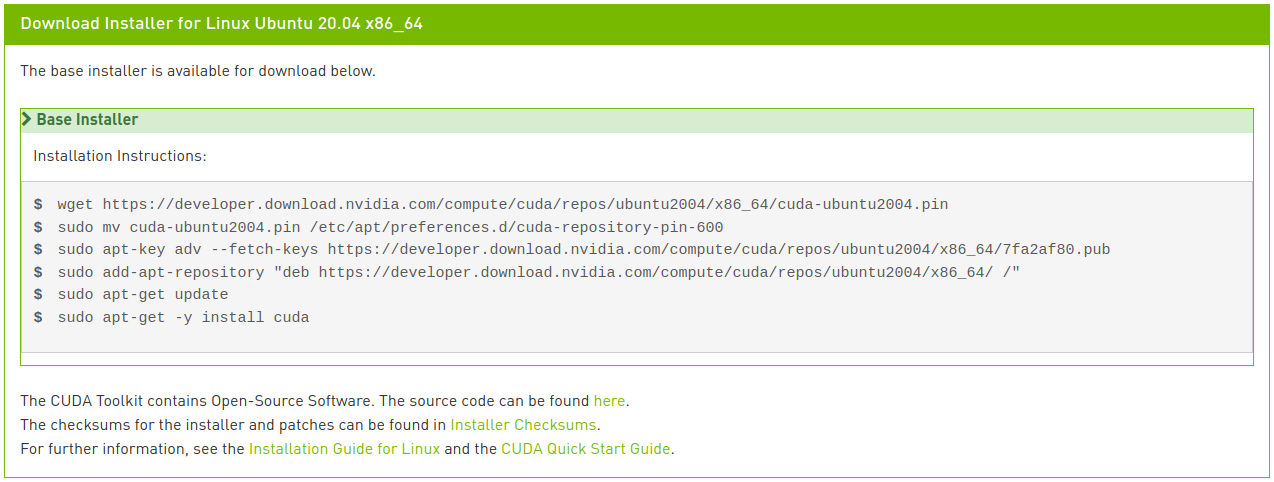
Exécutez les commandes suivantes pour installer CUDA :
1
2
3
4
5
6
$ wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/cuda-ubuntu2004.pin
$ sudo mv cuda-ubuntu2004.pin /etc/apt/preferences.d/cuda-repository-pin-600
$ sudo apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/7fa2af80.pub
$ sudo add-apt-repository "deb https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/ /"
$ sudo apt update
$ sudo apt install cuda-toolkit-11-0 cuda-drivers
Si vous êtes attentif, vous aurez remarqué que la dernière ligne diffère légèrement des instructions affichées dans l’image. Avec l’installation réseau, si vous entrez simplement cuda comme indiqué dans l’image, la version 11.2 (la plus récente) sera installée, ce qui n’est pas ce que nous voulons. Vous pouvez consulter diverses options de méta-paquets dans le guide d’installation Linux de CUDA 11.0. Nous avons modifié la dernière ligne pour spécifier l’installation de la version 11.0 du paquet CUDA Toolkit, tout en permettant la mise à jour automatique du paquet de pilotes.
5-3. Installation de cuDNN
Installez cuDNN comme suit :
1
2
$ sudo apt install libcudnn8=8.0.5.39-1+cuda11.0
$ sudo apt install libcudnn8-dev=8.0.5.39-1+cuda11.0
6. Installation de PyTorch
Si vous avez créé un environnement virtuel à l’étape 3, assurez-vous qu’il est activé avant de continuer. Si vous n’avez pas besoin de PyTorch, vous pouvez sauter cette étape.
Accédez au site de PyTorch, sélectionnez la version de PyTorch à installer (Stable), le système d’exploitation (Linux), le package (Pip), le langage (Python) et CUDA (11.0), puis suivez les instructions à l’écran.
1
(env) $ pip install torch==1.7.1+cu110 torchvision==0.8.2+cu110 torchaudio===0.7.2 -f https://download.pytorch.org/whl/torch_stable.html
Pour vérifier que PyTorch est correctement installé, lancez l’interpréteur Python et exécutez les commandes suivantes. Si un tenseur est renvoyé, l’installation est réussie.
1
2
3
4
5
6
7
8
9
10
11
12
(env) $ python3
Python 3.8.5 (default, Jul 28 2020, 12:59:40)
[GCC 9.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
>>> x = torch.rand(5, 3)
>>> print(x)"
tensor([[0.8187, 0.5925, 0.2768],
[0.9884, 0.8298, 0.8553],
[0.6350, 0.7243, 0.2323],
[0.9205, 0.9239, 0.9065],
[0.2424, 0.1018, 0.3426]])
Pour vérifier que le pilote GPU et CUDA sont activés et disponibles, exécutez la commande suivante :
1
2
>>> torch.cuda.is_available()
True
7. Installation de TensorFlow 2
Si vous n’avez pas besoin de TensorFlow, vous pouvez ignorer cette étape.
Si vous avez installé PyTorch dans un environnement virtuel à l’étape 6, désactivez cet environnement, puis revenez aux étapes 3 et 4 pour créer et activer un nouvel environnement virtuel avant de continuer. Si vous avez sauté l’étape 6, continuez simplement.
Installez TensorFlow comme suit :
1
(env2) $ pip install --upgrade tensorflow
Pour vérifier que TensorFlow est correctement installé, exécutez la commande suivante. Si le nom du GPU s’affiche et qu’un tenseur est renvoyé, l’installation est réussie.
1
2
3
4
5
6
(env2) $ python -c "import tensorflow as tf;print(tf.reduce_sum(tf.random.normal([1000, 1000])))"
2021-02-07 22:45:51.390640: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0
(abrégé)
2021-02-07 22:45:54.592749: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1406] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 6878 MB memory) -> physical GPU (device: 0, name: GeForce RTX 3070, pci bus id: 0000:01:00.0, compute capability: 8.6)
tf.Tensor(526.1059, shape=(), dtype=float32)