Configuración del entorno de desarrollo para Machine Learning
Este artículo trata sobre cómo configurar un entorno de desarrollo, que puede considerarse el primer paso para estudiar machine learning en una máquina local. Todo el contenido está escrito basándose en Ubuntu 20.04 LTS con una tarjeta gráfica NVIDIA Geforce RTX 3070.

Descripción general
Este artículo trata sobre cómo configurar un entorno de desarrollo, que puede considerarse el primer paso para estudiar machine learning en una máquina local. Todo el contenido está escrito basándose en Ubuntu 20.04 LTS con una tarjeta gráfica NVIDIA Geforce RTX 3070.
- Stack tecnológico a configurar
- Ubuntu 20.04 LTS
- Python 3.8
- pip 21.0.1
- jupyter
- matplotlib
- numpy
- pandas
- scipy
- scikit-learn
- CUDA 11.0.3
- cuDNN 8.0.5
- Frameworks de deep learning (se recomienda instalar solo uno por entorno)
- PyTorch 1.7.1
- TensorFlow 2.4.0
Tabla comparativa con la nueva guía de configuración del entorno de desarrollo para machine learning
Aunque han pasado aproximadamente 3 años y medio desde que subí este artículo al blog, su contenido sigue siendo válido en general, excepto por algunos detalles específicos como las versiones de paquetes o el lanzamiento de controladores de código abierto de NVIDIA. Sin embargo, al comprar una nueva PC y configurar el entorno de desarrollo en el verano del calendario holoceno 12024, hubo algunos cambios que me llevaron a escribir una nueva guía de configuración del entorno de desarrollo. Las diferencias se muestran en la siguiente tabla.
| Diferencia | Este artículo (versión 12021) | Nuevo artículo (versión 12024) |
|---|---|---|
| Distribución Linux | Basado en Ubuntu | Aplicable a Ubuntu y también Fedora/RHEL/Centos, Debian, openSUSE/SLES, etc. |
| Método de configuración | Entorno virtual Python usando venv | Entorno basado en contenedores Docker usando NVIDIA Container Toolkit |
| Instalación de controladores gráficos NVIDIA | Sí | Sí |
| Instalación directa de CUDA y cuDNN en el sistema host | Sí (usando el gestor de paquetes Apt) | No (se usan imágenes preinstaladas proporcionadas por NVIDIA en Docker Hub, por lo que no es necesario hacerlo manualmente) |
| Portabilidad | Necesidad de reconstruir el entorno cada vez que se migra a otro sistema | Al estar basado en Docker, se puede construir fácilmente una nueva imagen con el Dockerfile creado cuando sea necesario, o migrar fácilmente la imagen existente (excluyendo volúmenes adicionales o configuraciones de red) |
| Uso de bibliotecas de aceleración GPU adicionales además de cuDNN | No | Introducción de CuPy, cuDF, cuML, DALI |
| Interfaz de Jupyter Notebook | Jupyter Notebook (clásico) | JupyterLab (nueva generación) |
| Configuración del servidor SSH | No se trata | Incluye configuración básica del servidor SSH en la parte 3 |
Si prefieres usar entornos virtuales de Python como venv en lugar de Docker, este artículo sigue siendo válido, así que puedes continuar leyéndolo. Si quieres disfrutar de las ventajas de adoptar contenedores Docker, como la alta portabilidad, o si planeas usar distribuciones Linux distintas a Ubuntu, como Fedora, o si tienes una tarjeta gráfica NVIDIA y quieres utilizar bibliotecas de aceleración GPU adicionales como CuPy, cuDF, cuML, DALI, o si deseas acceder remotamente mediante configuraciones SSH y JupyterLab, te recomiendo consultar también la nueva guía.
0. Requisitos previos
- Se recomienda usar Linux para estudiar machine learning. Aunque es posible hacerlo en Windows, puede haber muchas pérdidas de tiempo en varios aspectos. Lo más sencillo es usar la última versión LTS de Ubuntu. Es conveniente porque los controladores propietarios se instalan automáticamente, y como tiene muchos usuarios, la mayoría de la documentación técnica está escrita para Ubuntu.
- Generalmente, Python viene preinstalado en la mayoría de las distribuciones Linux, incluido Ubuntu. Sin embargo, si Python no está instalado, debes instalarlo antes de seguir este artículo.
- Puedes verificar la versión actual de Python con el siguiente comando:
1
$ python3 --version
- Si vas a usar TensorFlow 2 o PyTorch, debes verificar las versiones de Python compatibles. En el momento de escribir este artículo, las versiones de Python compatibles con la última versión de PyTorch son 3.6-3.8, y las versiones de Python compatibles con la última versión de TensorFlow 2 son 3.5-3.8.
En este artículo, usamos Python 3.8.
- Puedes verificar la versión actual de Python con el siguiente comando:
- Si planeas estudiar machine learning en una máquina local, es recomendable tener al menos una GPU. Aunque el preprocesamiento de datos puede hacerse con CPU, la diferencia de velocidad entre CPU y GPU durante el entrenamiento del modelo es abrumadora a medida que el modelo se vuelve más grande (especialmente en deep learning).
- Para machine learning, realmente solo hay una opción de fabricante de GPU: debes usar productos NVIDIA. NVIDIA ha invertido considerablemente en el campo del machine learning, y casi todos los frameworks de machine learning utilizan la biblioteca CUDA de NVIDIA.
- Si planeas usar GPU para machine learning, primero debes verificar si tu tarjeta gráfica es un modelo compatible con CUDA. Puedes verificar el modelo de GPU instalado en tu computadora con el comando
uname -m && cat /etc/*releaseen la terminal. Busca el nombre del modelo en la lista de GPUs en este enlace y verifica el valor de Compute Capability. Este valor debe ser al menos 3.5 para poder usar CUDA. - Los criterios para seleccionar una GPU están bien resumidos en el siguiente artículo, que el autor actualiza continuamente:
Which GPU(s) to Get for Deep Learning
Otro artículo muy útil del mismo autor es A Full Hardware Guide to Deep Learning. La conclusión del artículo es la siguiente:The RTX 3070 and RTX 3080 are mighty cards, but they lack a bit of memory. For many tasks, however, you do not need that amount of memory.
The RTX 3070 is perfect if you want to learn deep learning. This is so because the basic skills of training most architectures can be learned by just scaling them down a bit or using a bit smaller input images. If I would learn deep learning again, I would probably roll with one RTX 3070, or even multiple if I have the money to spare. The RTX 3080 is currently by far the most cost-efficient card and thus ideal for prototyping. For prototyping, you want the largest memory, which is still cheap. With prototyping, I mean here prototyping in any area: Research, competitive Kaggle, hacking ideas/models for a startup, experimenting with research code. For all these applications, the RTX 3080 is the best GPU.
Si cumples con todos los requisitos mencionados anteriormente, comencemos a configurar el entorno de trabajo.
1. Crear directorio de trabajo
Abre la terminal y modifica el archivo .bashrc para registrar una variable de entorno (el comando viene después del prompt $).
Primero, abre el editor nano con el siguiente comando (también puedes usar vim u otro editor):
1
$ nano ~/.bashrc
Añade lo siguiente al final del archivo. Puedes cambiar la ruta dentro de las comillas dobles si lo deseas.
export ML_PATH="$HOME/ml"
Presiona Ctrl+O para guardar y luego Ctrl+X para salir.
Ahora ejecuta el siguiente comando para aplicar la variable de entorno:
1
$ source ~/.bashrc
Crea el directorio:
1
$ mkdir -p $ML_PATH
2. Instalar el gestor de paquetes pip
Hay varias formas de instalar los paquetes de Python necesarios para machine learning. Puedes usar una distribución científica de Python como Anaconda (recomendado para Windows), o puedes usar pip, la herramienta de empaquetado propia de Python. Aquí usaremos el comando pip en la shell bash de Linux o macOS.
Verifica si pip está instalado en tu sistema con el siguiente comando:
1
2
3
4
5
6
$ pip3 --version
El comando 'pip3' no se encuentra. Sin embargo, se puede instalar mediante:
sudo apt install python3-pip
Si aparece algo similar, pip no está instalado en tu sistema. Instálalo usando el gestor de paquetes del sistema (en este caso, apt) (si aparece un número de versión, pip ya está instalado, así que puedes omitir este comando):
1
$ sudo apt install python3-pip
Ahora pip está instalado en tu sistema.
3. Crear un entorno virtual independiente (recomendado)
Para crear un entorno virtual (para evitar conflictos de versiones de bibliotecas con otros proyectos), instala venv:
1
$ sudo apt install python3-venv
Luego, crea un entorno Python independiente de la siguiente manera. Esto se hace para evitar conflictos entre las versiones de bibliotecas necesarias para diferentes proyectos, así que debes crear un nuevo entorno virtual cada vez que inicies un nuevo proyecto:
1
2
$ cd $ML_PATH
$ python3 -m venv --system-site-packages ./(nombre del entorno)
Para activar este entorno virtual, abre una terminal e ingresa el siguiente comando:
1
2
$ cd $ML_PATH
$ source ./(nombre del entorno)/bin/activate
Después de activar el entorno virtual, actualiza pip dentro del entorno:
1
(env) $ pip install -U pip
Para desactivar el entorno virtual más tarde, usa el comando deactivate. Cuando el entorno está activado, cualquier paquete que instales con pip se instalará en este entorno independiente, y Python usará estos paquetes.
3′. (Si no creas un entorno virtual) Actualizar la versión de pip
Cuando instalas pip en el sistema, se descarga e instala un archivo binario desde el servidor espejo de la distribución (en este caso, Ubuntu), pero este archivo binario generalmente no es la última versión debido a actualizaciones lentas (en mi caso, se instaló la versión 20.3.4). Para usar la última versión de pip, ejecuta el siguiente comando para instalar (o actualizar si ya está instalado) pip en el directorio home del usuario:
1
2
3
4
5
$ python3 -m pip install -U pip
Collecting pip
(omitido)
Successfully installed pip-21.0.1
Puedes ver que pip se ha instalado en la versión 21.0.1, que es la más reciente en el momento de escribir este artículo. En este caso, pip instalado en el directorio home del usuario no es reconocido automáticamente por el sistema, así que debes registrarlo en la variable de entorno PATH para que el sistema lo reconozca y use.
Abre nuevamente el archivo .bashrc con un editor:
1
$ nano ~/.bashrc
Esta vez, busca la línea que comienza con export PATH=. Si no hay rutas escritas después, simplemente añade el contenido como hicimos en el paso 1. Si ya hay otras rutas registradas, añade el contenido al final usando dos puntos:
export PATH="$HOME/.local/bin"
export PATH="(ruta existente):$HOME/.local/bin"
Actualizar pip del sistema por métodos distintos al gestor de paquetes del sistema puede causar problemas debido a conflictos de versiones. Por eso instalamos pip por separado en el directorio home del usuario. Por la misma razón, es mejor usar el comando python3 -m pip en lugar de pip cuando no estés dentro de un entorno virtual.
4. Instalar paquetes para machine learning (jupyter, matplotlib, numpy, pandas, scipy, scikit-learn)
Instala los paquetes necesarios y todas sus dependencias con el siguiente comando pip:
En mi caso, uso venv, así que uso el comando pip, pero si no usas venv, se recomienda usar el comando python3 -m pip como se mencionó anteriormente.
1
2
3
4
5
6
(env) $ pip install -U jupyter matplotlib numpy pandas scipy scikit-learn
Collecting jupyter
Downloading jupyter-1.0.0-py2.py3-none-any.whl (2.7 kB)
Collecting matplotlib
(omitido)
Si usaste venv, registra un kernel en Jupyter y dale un nombre:
1
(env) $ python3 -m ipykernel install --user --name=(nombre del kernel)
Ahora puedes ejecutar Jupyter con el siguiente comando:
1
(env) $ jupyter notebook
5. Instalar CUDA & cuDNN
5-1. Verificar las versiones necesarias de CUDA & cuDNN
Verifica las versiones de CUDA compatibles en la documentación oficial de PyTorch:

Para PyTorch 1.7.1, las versiones de CUDA compatibles son 9.2, 10.1, 10.2 y 11.0. Las GPUs NVIDIA serie 30 requieren CUDA 11, así que necesitamos la versión 11.0.
También verifica las versiones necesarias de CUDA en la documentación oficial de TensorFlow 2:
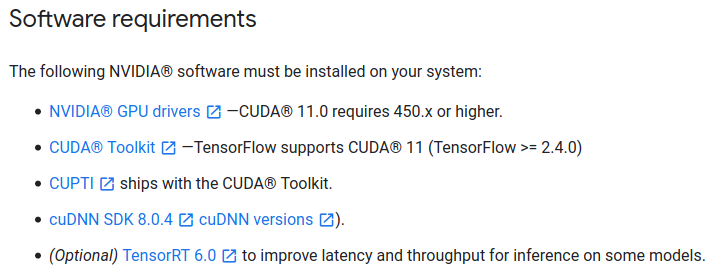
Para TensorFlow 2.4.0, también se necesita CUDA 11.0 y cuDNN 8.0.
Como a veces uso PyTorch y otras veces TensorFlow 2, verifiqué las versiones de CUDA compatibles con ambos paquetes. Debes verificar los requisitos del paquete que necesites y ajustarte a ellos.
5-2. Instalar CUDA
Visita el Archivo de CUDA Toolkit y selecciona la versión que verificaste anteriormente. En este artículo, seleccionamos CUDA Toolkit 11.0 Update1:
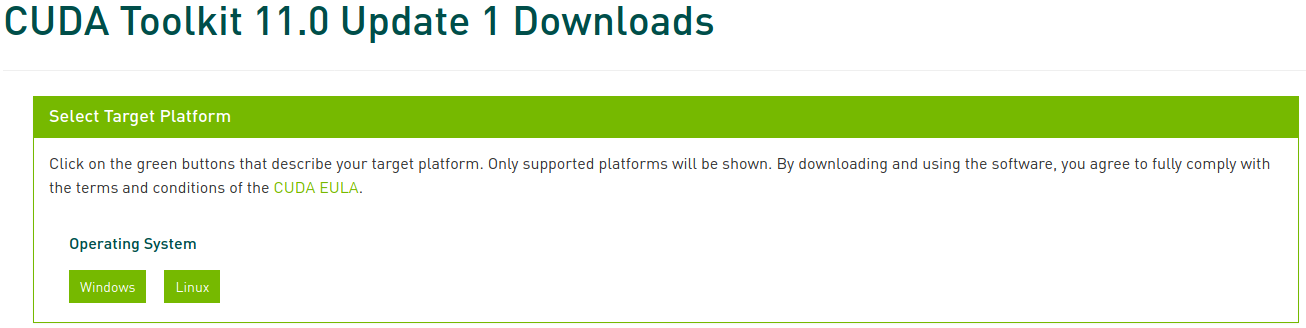
Ahora selecciona la plataforma correspondiente y el tipo de instalador, y sigue las instrucciones que aparecen en pantalla. Se recomienda usar el gestor de paquetes del sistema para el instalador cuando sea posible. Mi método preferido es deb (network):
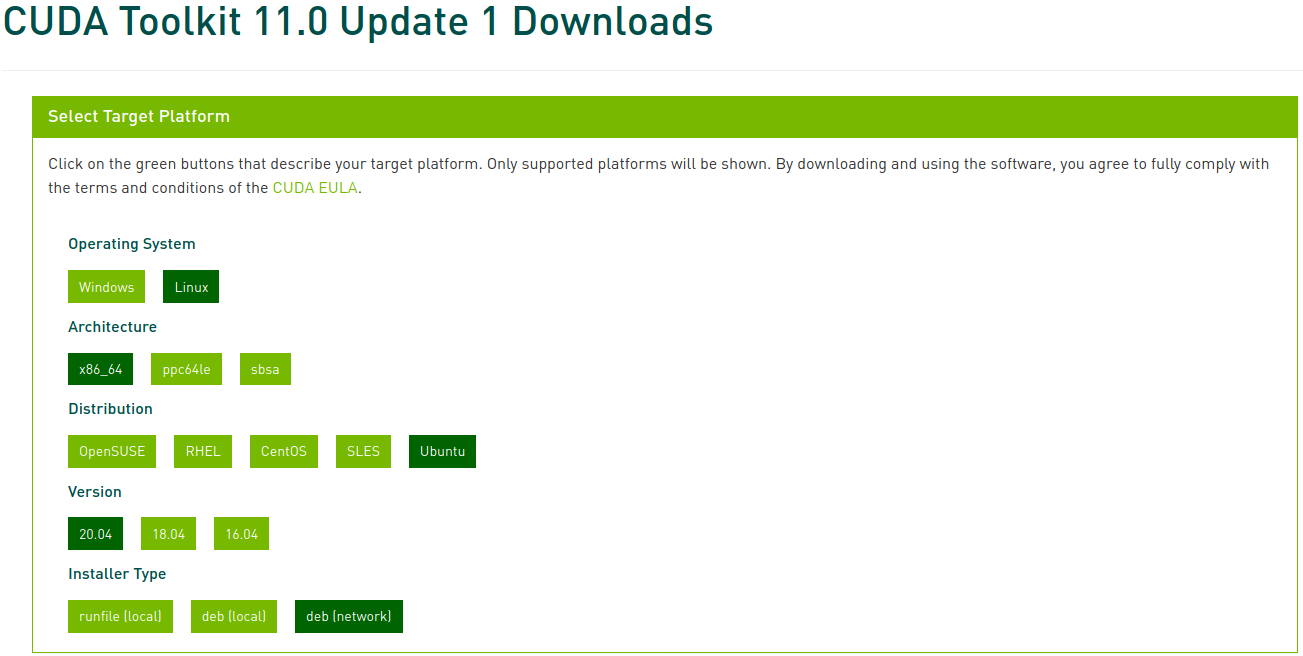
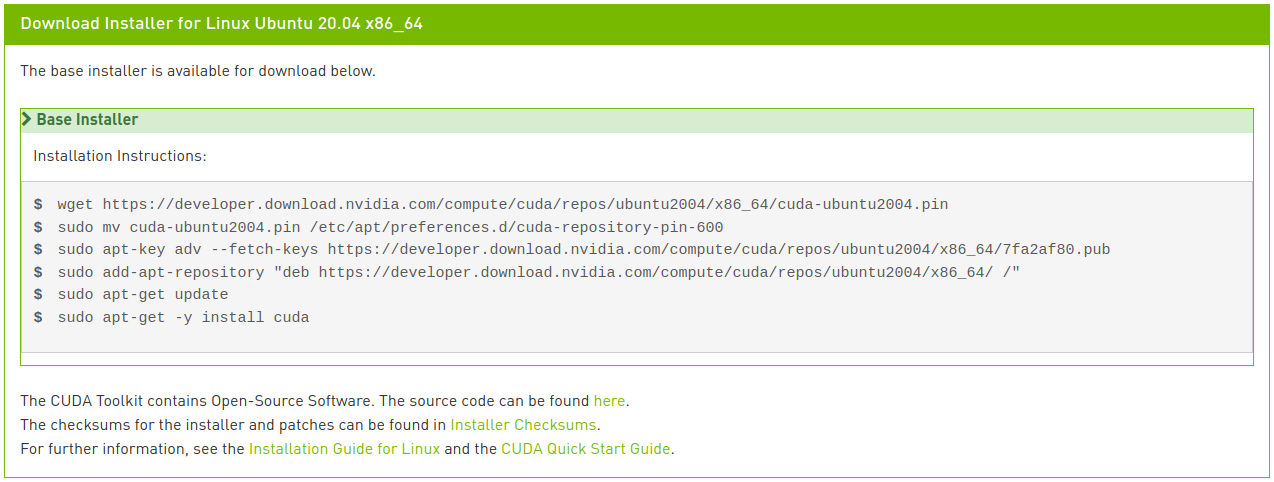
Ejecuta los siguientes comandos para instalar CUDA:
1
2
3
4
5
6
$ wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/cuda-ubuntu2004.pin
$ sudo mv cuda-ubuntu2004.pin /etc/apt/preferences.d/cuda-repository-pin-600
$ sudo apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/7fa2af80.pub
$ sudo add-apt-repository "deb https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/ /"
$ sudo apt update
$ sudo apt install cuda-toolkit-11-0 cuda-drivers
Si eres observador, habrás notado que la última línea es ligeramente diferente de las instrucciones mostradas en la imagen. En la instalación por red, si solo escribes cuda como se muestra en la imagen, se instalará la versión más reciente (11.2), lo cual no es lo que queremos. Puedes ver varias opciones de metapaquetes en la Guía de instalación de CUDA 11.0 para Linux. Aquí hemos modificado la última línea para instalar específicamente la versión 11.0 del paquete CUDA Toolkit y permitir que el paquete de controladores se actualice automáticamente.
5-3. Instalar cuDNN
Instala cuDNN con los siguientes comandos:
1
2
$ sudo apt install libcudnn8=8.0.5.39-1+cuda11.0
$ sudo apt install libcudnn8-dev=8.0.5.39-1+cuda11.0
6. Instalar PyTorch
Si creaste un entorno virtual en el paso 3, asegúrate de tenerlo activado antes de continuar. Si no necesitas PyTorch, puedes omitir este paso.
Visita la página web de PyTorch, selecciona la versión de PyTorch (Stable), el sistema operativo (Linux), el paquete (Pip), el lenguaje (Python) y CUDA (11.0), y sigue las instrucciones que aparecen en pantalla:
1
(env) $ pip install torch==1.7.1+cu110 torchvision==0.8.2+cu110 torchaudio===0.7.2 -f https://download.pytorch.org/whl/torch_stable.html
Para verificar que PyTorch se ha instalado correctamente, ejecuta el intérprete de Python y prueba los siguientes comandos. Si se devuelve un tensor, la instalación ha sido exitosa:
1
2
3
4
5
6
7
8
9
10
11
12
(env) $ python3
Python 3.8.5 (default, Jul 28 2020, 12:59:40)
[GCC 9.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
>>> x = torch.rand(5, 3)
>>> print(x)"
tensor([[0.8187, 0.5925, 0.2768],
[0.9884, 0.8298, 0.8553],
[0.6350, 0.7243, 0.2323],
[0.9205, 0.9239, 0.9065],
[0.2424, 0.1018, 0.3426]])
Para verificar que el controlador de GPU y CUDA están activados y disponibles, ejecuta el siguiente comando:
1
2
>>> torch.cuda.is_available()
True
7. Instalar TensorFlow 2
Si no necesitas TensorFlow, puedes omitir este paso.
Si instalaste PyTorch en un entorno virtual en el paso 6, desactiva ese entorno y vuelve a los pasos 3 y 4 para crear y activar un nuevo entorno virtual antes de continuar. Si omitiste el paso 6, simplemente continúa.
Instala TensorFlow con el siguiente comando:
1
(env2) $ pip install --upgrade tensorflow
Para verificar que TensorFlow se ha instalado correctamente, ejecuta el siguiente comando. Si muestra el nombre de la GPU y devuelve un tensor, la instalación ha sido exitosa:
1
2
3
4
5
6
(env2) $ python -c "import tensorflow as tf;print(tf.reduce_sum(tf.random.normal([1000, 1000])))"
2021-02-07 22:45:51.390640: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0
(omitido)
2021-02-07 22:45:54.592749: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1406] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 6878 MB memory) -> physical GPU (device: 0, name: GeForce RTX 3070, pci bus id: 0000:01:00.0, compute capability: 8.6)
tf.Tensor(526.1059, shape=(), dtype=float32)