Aufbau einer Machine-Learning-Entwicklungsumgebung
In diesem Artikel wird die Einrichtung einer Entwicklungsumgebung behandelt, die als erster Schritt zum Erlernen von maschinellem Lernen auf einem lokalen Rechner betrachtet werden kann. Alle Inhalte wurden auf Ubuntu 20.04 LTS mit einer NVIDIA Geforce RTX 3070 Grafikkarte erstellt.

Übersicht
In diesem Artikel wird die Einrichtung einer Entwicklungsumgebung behandelt, die als erster Schritt zum Erlernen von maschinellem Lernen auf einem lokalen Rechner betrachtet werden kann. Alle Inhalte wurden auf Ubuntu 20.04 LTS mit einer NVIDIA Geforce RTX 3070 Grafikkarte erstellt.
- Aufzubauender Technologie-Stack
- Ubuntu 20.04 LTS
- Python 3.8
- pip 21.0.1
- jupyter
- matplotlib
- numpy
- pandas
- scipy
- scikit-learn
- CUDA 11.0.3
- cuDNN 8.0.5
- Deep-Learning-Frameworks (es wird empfohlen, nur eines pro Umgebung zu installieren)
- PyTorch 1.7.1
- TensorFlow 2.4.0
Vergleichstabelle mit dem neu erstellten Machine-Learning-Entwicklungsumgebungs-Leitfaden
Obwohl seit der Veröffentlichung dieses Artikels im Blog etwa dreieinhalb Jahre vergangen sind, ist der Inhalt dieses Artikels abgesehen von einigen Details wie Paketversionen oder der Veröffentlichung von NVIDIA Open-Source-Treibern im Großen und Ganzen noch gültig. Als ich jedoch im Sommer 12024 des Holozän-Kalenders einen neuen PC kaufte und eine Entwicklungsumgebung einrichtete, gab es einige Änderungen, weshalb ich einen neuen Leitfaden zur Einrichtung einer Entwicklungsumgebung erstellt habe. Die Unterschiede sind in der folgenden Tabelle aufgeführt.
| Unterschied | Dieser Artikel (Version 12021) | Neuer Artikel (Version 12024) |
|---|---|---|
| Linux-Distribution | Basierend auf Ubuntu | Anwendbar auf Ubuntu sowie Fedora/RHEL/Centos, Debian, openSUSE/SLES usw. |
| Methode zum Aufbau der Entwicklungsumgebung | Python-Virtualenv mit venv | Docker-Container-basierte Umgebung mit NVIDIA Container Toolkit |
| Installation des NVIDIA-Grafiktreibers | O | O |
| Direkte Installation von CUDA und cuDNN auf dem Host-System | O (mit Apt-Paketmanager) | X (Verwendung von vorinstallierten Images von NVIDIA auf Docker Hub, daher keine direkte Arbeit erforderlich) |
| Portabilität | Bei jedem Systemwechsel muss die Entwicklungsumgebung neu aufgebaut werden | Docker-basiert, daher kann mit der erstellten Dockerfile bei Bedarf ein neues Image erstellt oder das bestehende Image (ohne zusätzliche Volumes oder Netzwerkeinstellungen) leicht portiert werden |
| Nutzung zusätzlicher GPU- Beschleunigungsbibliotheken neben cuDNN | X | Einführung von CuPy, cuDF, cuML, DALI |
| Jupyter Notebook-Oberfläche | Jupyter Notebook (klassisch) | JupyterLab (Next-Generation) |
| SSH-Server-Konfiguration | Nicht behandelt | Teil 3 enthält eine grundlegende SSH-Server-Konfiguration |
Wenn du lieber Python-Virtualenvs wie venv anstelle von Docker verwenden möchtest, ist dieser Artikel nach wie vor gültig und du kannst ihn weiterhin lesen. Wenn du jedoch die Vorteile von Docker-Containern wie hohe Portabilität nutzen möchtest, eine andere Linux-Distribution als Ubuntu wie Fedora verwenden willst, eine Umgebung mit NVIDIA-Grafikkarte hast und zusätzliche GPU-Beschleunigungsbibliotheken wie CuPy, cuDF, cuML oder DALI nutzen möchtest, oder wenn du per SSH und JupyterLab remote zugreifen möchtest, empfehle ich dir, auch den neuen Leitfaden zu konsultieren.
0. Voraussetzungen
- Für das Erlernen von maschinellem Lernen wird Linux empfohlen. Es ist zwar auch unter Windows möglich, aber es kann in verschiedenen Bereichen zu Zeitverschwendung kommen. Die neueste LTS-Version von Ubuntu ist die sicherste Wahl. Nicht-Open-Source-Treiber werden automatisch installiert, was bequem ist, und aufgrund der großen Benutzerbasis sind die meisten technischen Dokumente für Ubuntu geschrieben.
- In der Regel ist Python in den meisten Linux-Distributionen, einschließlich Ubuntu, vorinstalliert. Falls Python jedoch nicht installiert ist, solltest du es vor dem Befolgen dieses Artikels installieren.
- Die aktuell installierte Python-Version kann mit folgendem Befehl überprüft werden:
1
$ python3 --version
- Wenn du TensorFlow 2 oder PyTorch verwenden möchtest, solltest du die kompatiblen Python-Versionen überprüfen. Zum Zeitpunkt der Erstellung dieses Artikels unterstützt die neueste Version von PyTorch Python-Versionen 3.6-3.8, und die neueste Version von TensorFlow 2 unterstützt Python-Versionen 3.5-3.8.
In diesem Artikel verwenden wir Python 3.8.
- Die aktuell installierte Python-Version kann mit folgendem Befehl überprüft werden:
- Wenn du maschinelles Lernen auf deinem lokalen Rechner lernen möchtest, ist es ratsam, mindestens eine GPU vorzubereiten. Datenvorverarbeitung kann zwar auch mit der CPU durchgeführt werden, aber in der Modelltrainingsphase wird der Geschwindigkeitsunterschied zwischen CPU und GPU mit zunehmender Modellgröße überwältigend (besonders bei Deep Learning).
- Für maschinelles Lernen gibt es praktisch nur eine Wahl für den GPU-Hersteller: NVIDIA. NVIDIA hat stark in den Bereich des maschinellen Lernens investiert, und fast alle Machine-Learning-Frameworks verwenden die CUDA-Bibliothek von NVIDIA.
- Wenn du eine GPU für maschinelles Lernen verwenden möchtest, solltest du zunächst überprüfen, ob dein Grafikkartenmodell CUDA unterstützt. Der Name des in deinem Computer installierten GPU-Modells kann im Terminal mit dem Befehl
uname -m && cat /etc/*releaseüberprüft werden. Suche das entsprechende Modell in der GPU-Liste unter diesem Link und überprüfe den Wert Compute Capability. Dieser Wert sollte mindestens 3.5 betragen, damit CUDA verwendet werden kann. - Die Kriterien für die GPU-Auswahl sind in folgendem Artikel gut zusammengefasst. Der Autor aktualisiert den Artikel kontinuierlich.
Which GPU(s) to Get for Deep Learning
Ein weiterer nützlicher Artikel desselben Autors ist A Full Hardware Guide to Deep Learning. Die Schlussfolgerung des obigen Artikels lautet wie folgt:The RTX 3070 and RTX 3080 are mighty cards, but they lack a bit of memory. For many tasks, however, you do not need that amount of memory.
The RTX 3070 is perfect if you want to learn deep learning. This is so because the basic skills of training most architectures can be learned by just scaling them down a bit or using a bit smaller input images. If I would learn deep learning again, I would probably roll with one RTX 3070, or even multiple if I have the money to spare. The RTX 3080 is currently by far the most cost-efficient card and thus ideal for prototyping. For prototyping, you want the largest memory, which is still cheap. With prototyping, I mean here prototyping in any area: Research, competitive Kaggle, hacking ideas/models for a startup, experimenting with research code. For all these applications, the RTX 3080 is the best GPU.
Wenn alle oben genannten Anforderungen erfüllt sind, können wir mit dem Aufbau der Arbeitsumgebung beginnen.
1. Erstellen des Arbeitsverzeichnisses
Öffne ein Terminal und bearbeite die .bashrc-Datei, um Umgebungsvariablen zu registrieren (der Befehl folgt nach dem $-Prompt).
Öffne zunächst den Nano-Editor mit folgendem Befehl (vim oder ein anderer Editor ist auch in Ordnung):
1
$ nano ~/.bashrc
Füge am Ende der Datei Folgendes hinzu. Der Inhalt in Anführungszeichen kann bei Bedarf in einen anderen Pfad geändert werden.
export ML_PATH="$HOME/ml"
Drücke Strg+O zum Speichern und dann Strg+X zum Beenden.
Führe nun den folgenden Befehl aus, um die Umgebungsvariable zu aktivieren:
1
$ source ~/.bashrc
Erstelle das Verzeichnis:
1
$ mkdir -p $ML_PATH
2. Installation des pip-Paketmanagers
Es gibt verschiedene Möglichkeiten, die für maschinelles Lernen erforderlichen Python-Pakete zu installieren. Du kannst eine wissenschaftliche Python-Distribution wie Anaconda verwenden (empfohlen für Windows-Betriebssysteme) oder das native Python-Packaging-Tool pip. Hier werden wir den pip-Befehl in der Bash-Shell unter Linux oder macOS verwenden.
Überprüfe mit folgendem Befehl, ob pip auf deinem System installiert ist:
1
2
3
4
5
6
$ pip3 --version
Befehl 'pip3' nicht gefunden. Er kann jedoch installiert werden mit:
sudo apt install python3-pip
Wenn du eine ähnliche Ausgabe erhältst, ist pip nicht auf deinem System installiert. Installiere es mit dem Paketmanager deines Systems (hier apt) (wenn eine Versionsnummer angezeigt wird, ist es bereits installiert, und du kannst diesen Befehl überspringen):
1
$ sudo apt install python3-pip
Jetzt ist pip auf deinem System installiert.
3. Erstellen einer unabhängigen virtuellen Umgebung (empfohlen)
Um eine virtuelle Umgebung zu erstellen (um Konflikte mit Bibliotheksversionen anderer Projekte zu vermeiden), installiere venv:
1
$ sudo apt install python3-venv
Erstelle dann eine unabhängige Python-Umgebung wie folgt. Der Grund dafür ist, dass jedes Projekt unterschiedliche Bibliotheksversionen benötigen kann, die in Konflikt geraten könnten. Daher solltest du für jedes neue Projekt eine neue virtuelle Umgebung erstellen, um eine isolierte Umgebung zu gewährleisten.
1
2
$ cd $ML_PATH
$ python3 -m venv --system-site-packages ./(Umgebungsname)
Um diese virtuelle Umgebung zu aktivieren, öffne ein Terminal und gib Folgendes ein:
1
2
$ cd $ML_PATH
$ source ./(Umgebungsname)/bin/activate
Nach der Aktivierung der virtuellen Umgebung aktualisiere pip innerhalb der virtuellen Umgebung:
1
(env) $ pip install -U pip
Um die virtuelle Umgebung später zu deaktivieren, verwende den Befehl deactivate. Wenn die Umgebung aktiviert ist, wird jedes mit pip installierte Paket in dieser isolierten Umgebung installiert, und Python wird diese Pakete verwenden.
3′. (Falls keine virtuelle Umgebung erstellt wird) Aktualisierung der pip-Version
Bei der Installation von pip auf dem System wird eine Binärdatei vom Mirror-Server der Distribution (hier Ubuntu) heruntergeladen und installiert. Diese Binärdatei ist oft nicht die neueste Version, da Updates verzögert sein können (in meinem Fall wurde Version 20.3.4 installiert). Um die neueste Version von pip zu verwenden, führe den folgenden Befehl aus, um pip im Home-Verzeichnis des Benutzers zu installieren (oder zu aktualisieren, falls bereits installiert):
1
2
3
4
5
$ python3 -m pip install -U pip
Collecting pip
(gekürzt)
Successfully installed pip-21.0.1
Wie zu sehen ist, wurde pip auf Version 21.0.1 aktualisiert, die zum Zeitpunkt der Erstellung dieses Artikels die neueste Version war. Da das im Benutzer-Home-Verzeichnis installierte pip vom System nicht automatisch erkannt wird, muss es als PATH-Umgebungsvariable registriert werden, damit das System es erkennen und verwenden kann.
Öffne erneut die .bashrc-Datei mit einem Editor:
1
$ nano ~/.bashrc
Suche diesmal nach der Zeile, die mit export PATH= beginnt. Wenn keine Pfade dahinter stehen, füge den Inhalt einfach wie in Schritt 1 hinzu. Wenn bereits andere Pfade registriert sind, füge den Inhalt mit einem Doppelpunkt dahinter hinzu:
export PATH="$HOME/.local/bin"
export PATH="(bestehender Pfad):$HOME/.local/bin"
Die Aktualisierung des System-pip auf andere Weise als über den System-Paketmanager kann zu Versionskonflikten führen. Deshalb installieren wir pip separat im Home-Verzeichnis des Benutzers. Aus demselben Grund ist es ratsam, außerhalb einer virtuellen Umgebung den Befehl python3 -m pip anstelle von pip zu verwenden.
4. Installation von Machine-Learning-Paketen (jupyter, matplotlib, numpy, pandas, scipy, scikit-learn)
Installiere mit dem folgenden pip-Befehl alle benötigten Pakete und ihre Abhängigkeiten.
Da ich venv verwende, benutze ich einfach den pip-Befehl. Wenn du venv nicht verwendest, empfehle ich wie bereits erwähnt, stattdessen den Befehl python3 -m pip zu verwenden.
1
2
3
4
5
6
(env) $ pip install -U jupyter matplotlib numpy pandas scipy scikit-learn
Collecting jupyter
Downloading jupyter-1.0.0-py2.py3-none-any.whl (2.7 kB)
Collecting matplotlib
(gekürzt)
Wenn du venv verwendest, registriere den Kernel in Jupyter und gib ihm einen Namen:
1
(env) $ python3 -m ipykernel install --user --name=(Kernelname)
Um Jupyter ab jetzt zu starten, verwende den folgenden Befehl:
1
(env) $ jupyter notebook
5. Installation von CUDA & cuDNN
5-1. Überprüfung der benötigten CUDA & cuDNN-Versionen
Überprüfe die unterstützten CUDA-Versionen in der offiziellen PyTorch-Dokumentation.

Für PyTorch Version 1.7.1 werden die CUDA-Versionen 9.2, 10.1, 10.2 und 11.0 unterstützt. Da NVIDIA 30-Series-GPUs CUDA 11 benötigen, wissen wir, dass Version 11.0 erforderlich ist.
Überprüfe auch die benötigte CUDA-Version in der offiziellen TensorFlow 2-Dokumentation.
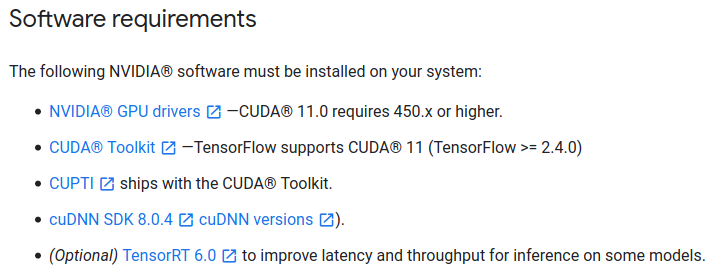
Für TensorFlow Version 2.4.0 wird ebenfalls CUDA Version 11.0 und cuDNN Version 8.0 benötigt.
Da ich je nach Situation sowohl PyTorch als auch TensorFlow 2 verwende, habe ich die CUDA-Versionen überprüft, die mit beiden Paketen kompatibel sind. Du solltest die Anforderungen der Pakete überprüfen, die du benötigst, und dich danach richten.
5-2. Installation von CUDA
Besuche das CUDA Toolkit Archive und wähle die zuvor ermittelte Version aus. In diesem Artikel wählen wir CUDA Toolkit 11.0 Update1.
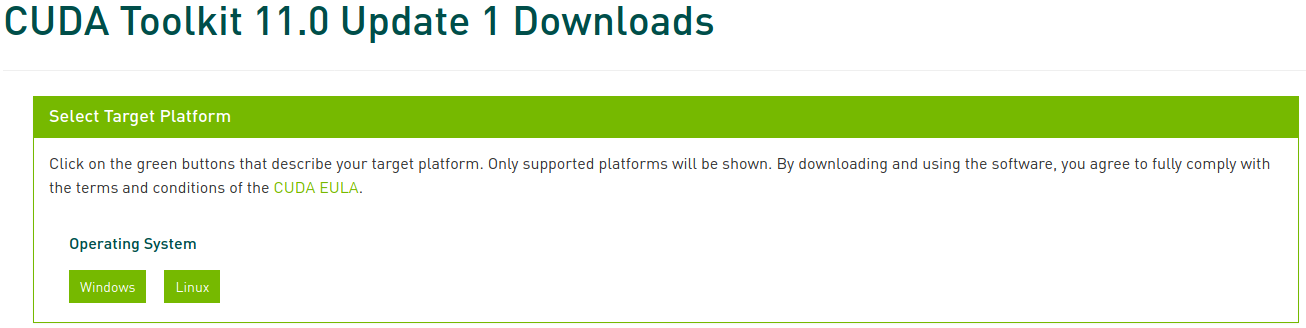
Wähle nun die entsprechende Plattform und den Installertyp aus und folge den Anweisungen auf dem Bildschirm. Es wird empfohlen, wenn möglich den Systempaketmanager für die Installation zu verwenden. Ich bevorzuge die Methode deb (network).
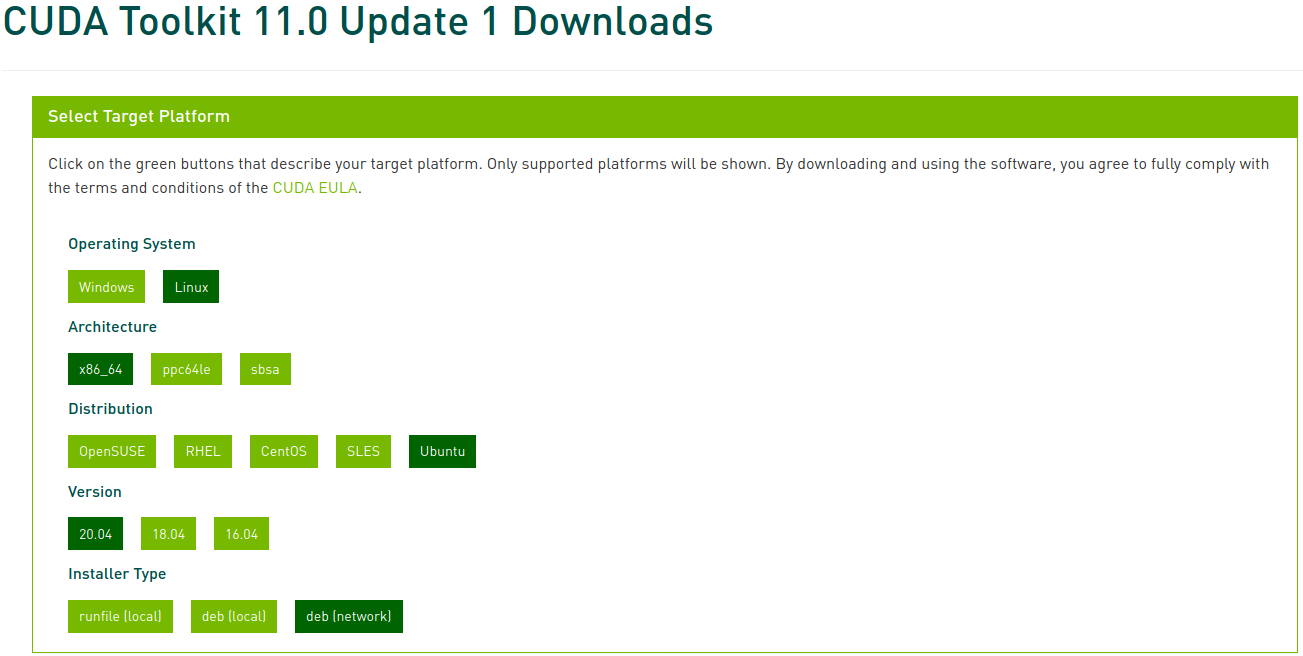
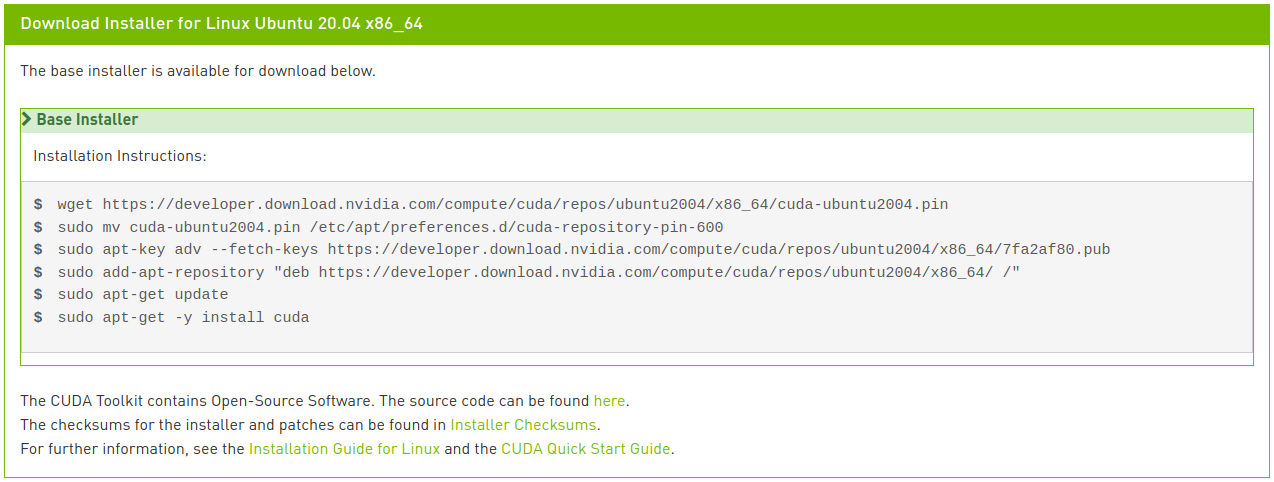
Führe die folgenden Befehle aus, um CUDA zu installieren:
1
2
3
4
5
6
$ wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/cuda-ubuntu2004.pin
$ sudo mv cuda-ubuntu2004.pin /etc/apt/preferences.d/cuda-repository-pin-600
$ sudo apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/7fa2af80.pub
$ sudo add-apt-repository "deb https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/ /"
$ sudo apt update
$ sudo apt install cuda-toolkit-11-0 cuda-drivers
Wenn du aufmerksam bist, hast du vielleicht bemerkt, dass die letzte Zeile etwas anders ist als die Anweisung im Bild. Bei der Netzwerkinstallation würde die Eingabe von nur “cuda”, wie im Bild gezeigt, die neueste Version 11.2 installieren, was nicht das ist, was wir wollen. Im CUDA 11.0 Linux-Installationsleitfaden findest du verschiedene Meta-Paketoptionen. Hier haben wir die letzte Zeile geändert, um das CUDA Toolkit-Paket in Version 11.0 zu installieren und das Treiberpaket automatisch aktualisieren zu lassen.
5-3. Installation von cuDNN
Installiere cuDNN wie folgt:
1
2
$ sudo apt install libcudnn8=8.0.5.39-1+cuda11.0
$ sudo apt install libcudnn8-dev=8.0.5.39-1+cuda11.0
6. Installation von PyTorch
Wenn du in Schritt 3 eine virtuelle Umgebung erstellt hast, aktiviere diese vor dem Fortfahren. Wenn du PyTorch nicht benötigst, überspringe diesen Schritt.
Besuche die PyTorch-Website, wähle den zu installierenden PyTorch-Build (Stable), das Betriebssystem (Linux), das Paket (Pip), die Sprache (Python) und CUDA (11.0) aus und folge den Anweisungen auf dem Bildschirm.
1
(env) $ pip install torch==1.7.1+cu110 torchvision==0.8.2+cu110 torchaudio===0.7.2 -f https://download.pytorch.org/whl/torch_stable.html
Um zu überprüfen, ob PyTorch korrekt installiert wurde, starte den Python-Interpreter und führe die folgenden Befehle aus. Wenn ein Tensor zurückgegeben wird, war die Installation erfolgreich.
1
2
3
4
5
6
7
8
9
10
11
12
(env) $ python3
Python 3.8.5 (default, Jul 28 2020, 12:59:40)
[GCC 9.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
>>> x = torch.rand(5, 3)
>>> print(x)"
tensor([[0.8187, 0.5925, 0.2768],
[0.9884, 0.8298, 0.8553],
[0.6350, 0.7243, 0.2323],
[0.9205, 0.9239, 0.9065],
[0.2424, 0.1018, 0.3426]])
Um zu überprüfen, ob der GPU-Treiber und CUDA aktiviert und verfügbar sind, führe den folgenden Befehl aus:
1
2
>>> torch.cuda.is_available()
True
7. Installation von TensorFlow 2
Wenn du TensorFlow nicht benötigst, überspringe diesen Schritt.
Wenn du PyTorch in Schritt 6 in einer virtuellen Umgebung installiert hast, deaktiviere diese Umgebung, kehre zu den Schritten 3 und 4 zurück, erstelle und aktiviere eine neue virtuelle Umgebung und fahre dann fort. Wenn du Schritt 6 übersprungen hast, fahre einfach fort.
Installiere TensorFlow wie folgt:
1
(env2) $ pip install --upgrade tensorflow
Um zu überprüfen, ob TensorFlow korrekt installiert wurde, führe den folgenden Befehl aus. Wenn der GPU-Name angezeigt wird und ein Tensor zurückgegeben wird, war die Installation erfolgreich.
1
2
3
4
5
6
(env2) $ python -c "import tensorflow as tf;print(tf.reduce_sum(tf.random.normal([1000, 1000])))"
2021-02-07 22:45:51.390640: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0
(gekürzt)
2021-02-07 22:45:54.592749: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1406] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 6878 MB memory) -> physical GPU (device: 0, name: GeForce RTX 3070, pci bus id: 0000:01:00.0, compute capability: 8.6)
tf.Tensor(526.1059, shape=(), dtype=float32)